文章摘要
【关 键 词】 AI爬虫、内容付费、网络流量、版权争议、数据经济
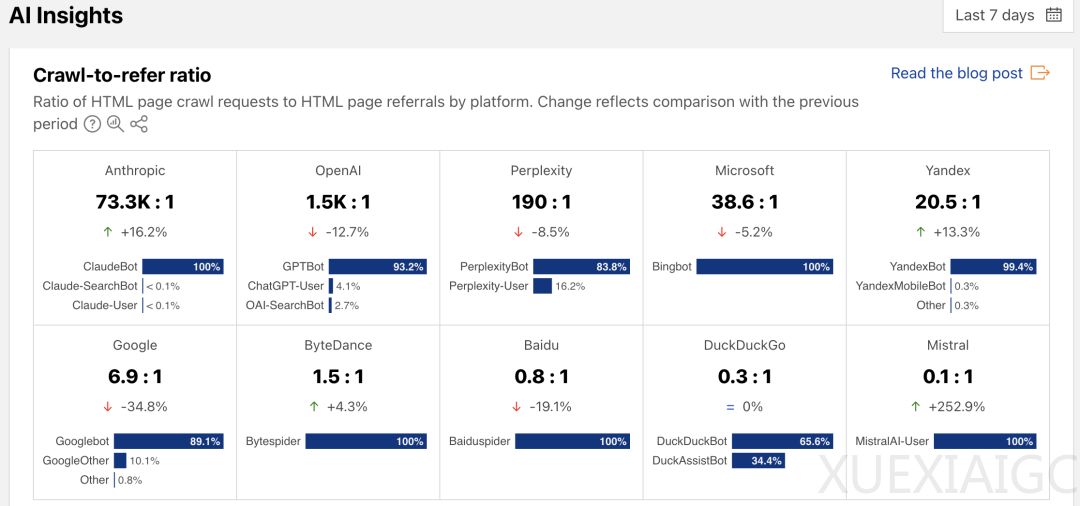
Cloudflare推出的「Pay Per Crawl」功能试图重构AI时代的内容付费模式,为网站创作者提供对抗AI爬虫肆意抓取的工具。这一实验性产品允许网站所有者选择对AI爬虫实施允许、封锁或按次收费的访问控制,旨在解决传统「内容换流量」模式在AI时代的失效问题。数据显示,OpenAI等AI公司的爬虫抓取与网站流量回报比例严重失衡,Anthropic的爬虫甚至需要73300次抓取才能为网站带来1次点击,导致原创内容创作者难以获得合理收益。
该系统的技术核心在于利用Cloudflare全球网络的中介地位,通过HTTP 402状态码强制实施支付验证,并要求AI公司注册数字签名密钥以防止规避。这种机制将原本依赖robots.txt的「软约束」转化为具有经济杠杆的「硬闸门」。目前已有部分主流出版商参与测试,长期目标是通过程序化支付体系,使各类网站都能获得AI训练数据的合理补偿。
这一变革可能引发深远影响:既可能终结AI公司免费获取网络内容的时代,也可能抬高AI研发的数据获取门槛。支持者认为这能促进高价值内容创作,反对者则担忧会加剧大厂垄断或阻碍学术研究。Cloudflare强调其方案保留网站自主选择权,但承认该模式仍处于早期阶段,需要与经济学家共同探索定价策略和生态平衡。
「Pay Per Crawl」标志着互联网经济模式面临根本性转折——当AI生成内容逐步替代传统网页访问时,如何界定数据所有权与价值分配成为关键命题。尽管存在争议,该实验首次为内容创作者提供了与AI巨头议价的标准化工具,其发展或将重塑数字内容的生产、流通与变现逻辑。正如Cloudflare所言,这不仅是技术方案,更是「互联网商业模式必须适应AI时代」的宣言。
原文和模型
【原文链接】 阅读原文 [ 3392字 | 14分钟 ]
【原文作者】 极客公园
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


