文章摘要
【关 键 词】 视频生成、智能体框架、开源工具、多模态、AI导演
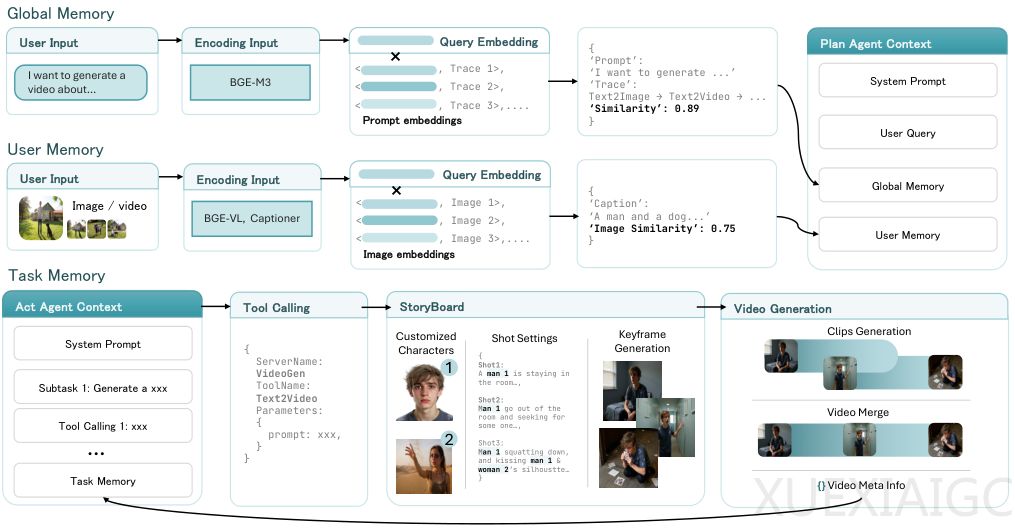
视频生成领域长期面临工具碎片化的困境,专业模型虽在单一任务上表现优异,但缺乏整合能力。为解决这一问题,新加坡管理大学、香港中文大学和斯坦福大学联合推出开源框架UniVA(Universal Video Agent),通过Plan-and-Act双智能体架构实现视频理解、分割、编辑和生成的全流程自动化。规划智能体负责解析用户意图并拆解任务步骤,执行智能体则通过标准化协议调用专业工具,二者配合形成闭环工作流。
为保障复杂流程的连贯性,系统采用三级内存机制:全局内存存储通用知识,任务内存维护中间产物,用户内存记录个性化偏好。这种设计使AI能像人类创作者一样保持上下文记忆,支持多轮迭代修改。工具集通过MCP协议实现模块化管理,新功能只需注册即可接入,无需修改核心代码,显著提升系统扩展性。
研发团队建立UniVA-Bench基准测试体系,首次将评估重点从单任务性能转向端到端工作流。测试表明,在长文本生成视频任务中,UniVA的CLIP分数达0.2814,远超传统模型;在视频编辑场景中,其通过语义理解实现跨镜头对象精准修改;人类评估显示UniVA在四个维度上获得最高偏好分,验证了其规划质量的优越性。典型案例显示,该系统能保持20秒视频中角色的身份一致性,并实现非线性叙事编排。
该框架已应用于网页端视频编辑工具,用户通过自然语言指令即可触发智能体工作。相比单智能体架构,双智能体设计使任务成功率提升125%,且支持在AI生成与手动编辑间无缝切换。研究证实,Claude-Sonnet-4作为规划者在故障恢复方面表现最佳,而内存机制使视频主题一致性提升2倍以上。这种集成化方案标志着视频创作从工具集合向智能工作流的范式转变。
原文和模型
【原文链接】 阅读原文 [ 4802字 | 20分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


