与DeepSeek-OCR不谋而合,NeurIPS论文提出让LLM像人一样读长文本
文章摘要
在 NeurIPS 2025 论文中,来自南京理工大学、中南大学、南京林业大学的研究团队提出了一个极具突破性的框架 ——VIST(Vision-centric Token Compression in LLM),为大语言模型的长文本高效推理提供了全新的 “视觉解决方案”。 这一框架通过模仿人类阅读的“快–慢通路”机制,显著提升了模型处理长文本的效率。研究背景源于当前大语言模型面临的“上下文长度激增”与“模型参数量膨胀”双重挑战,传统文本分词方式已难以满足海量信息处理需求。
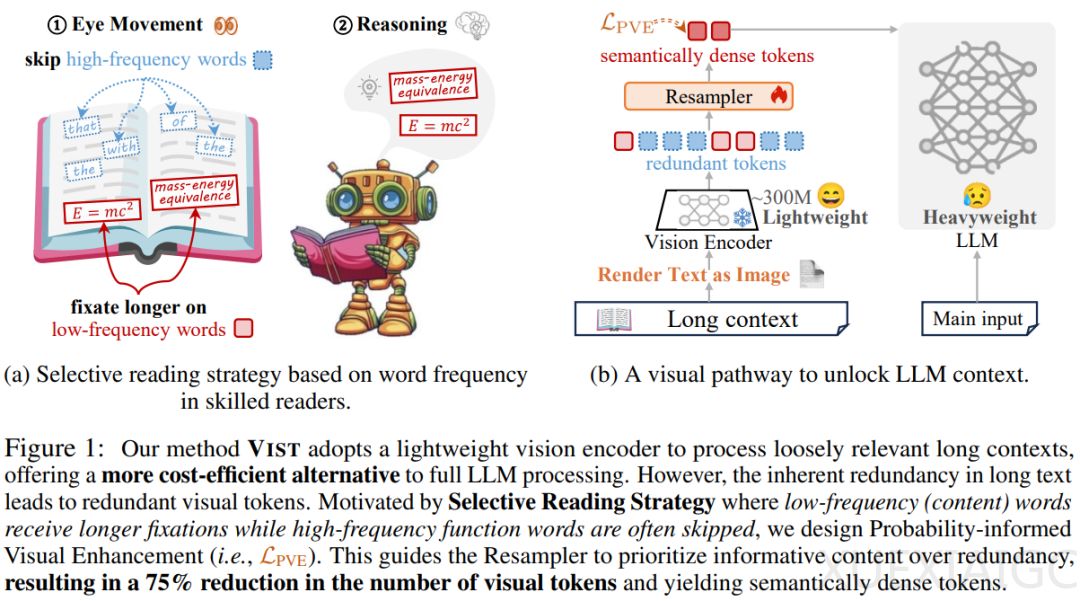
VIST 的核心思想是让大模型具备“选择性阅读”能力,通过视觉化压缩机制实现高效理解。 快路径(Fast Path)将次要上下文渲染为图像,由轻量级视觉编码器快速提取语义;慢路径(Slow Path)则直接处理关键文本,用于深度推理。这种双通道协作使模型在相同文本内容下,视觉 Token 数量减少 56%,内存降低 50%。研究显示,VIST 在开放域问答和 11 个 In-Context Learning 基准任务中显著优于传统文本压缩方法,甚至在极端条件下仍能保持可靠性能。
为优化视觉编码器对文本的理解,VIST 引入了概率感知视觉增强(PVE)机制。通过基于频率的屏蔽策略,模型能够自动忽略高频低信息量词汇,专注于名词、动词等核心内容。 这一设计使视觉压缩模块更精准高效,同时降低算力消耗。此外,视觉文本分词器(Visual Text Tokenization)的运用带来了四大优势:简化预处理流程、突破多语言词表限制、增强对字符级噪声的鲁棒性,以及显著提升多语言处理效率。
VIST 的突破性在于将视觉与语言处理深度融合,为大模型长文本理解开辟了新路径。 它不仅模拟了人类阅读的高效策略,还为多模态场景提供了可行方案。未来,视觉驱动的 Token 压缩有望成为长上下文 LLM 的标准组件,助力模型在保证性能的同时降低计算成本。该研究的潜在应用场景包括长文档分析、跨语言信息处理及抗干扰文本理解等领域,为下一代多模态智能系统的发展奠定了基础。
原文和模型
【原文链接】 阅读原文 [ 2027字 | 9分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


