文章摘要
【关 键 词】 人工智能、机器人技术、视觉语言模型、推理能力、具身智能
中科院自动化所、清华大学与GigaAI联合发布了视觉-语言-行动(VLA)模型的R1推理版本,该模型通过引入思维链机制和强化学习策略,显著提升了机器人在复杂环境中的任务执行能力。传统机器人模型直接输出动作指令,缺乏中间推理过程,而VLA-R1通过分阶段训练实现了”先思考后行动”的范式突破。
模型的核心创新在于将人类思维链(CoT)融入训练框架。研究团队构建了包含13,000个任务场景的VLA-CoT-13K数据集,由Qwen2.5-VL-72B模型自动生成详细推理步骤。例如执行”移动绿色积木”指令时,模型会依次完成目标识别、物体定位、路径规划等逻辑推理。这种结构化学习方式使机器人能分解复杂任务,将视觉感知与动作目标建立明确关联。模型架构采用Qwen2.5-VL-3B为基础,其重新设计的视觉Transformer可高效处理高分辨率图像,结合语言解码器生成包含推理过程和7D动作指令的结构化输出。
在强化学习阶段,研究团队开发了基于可验证奖励的RLVR策略,通过三位”考官”系统评估模型表现:轨迹考官使用角度长度增强Fréchet距离(ALAF)评估运动路径质量;空间定位考官采用广义交并比(GIoU)衡量物体识别精度;格式考官确保输出严格遵循”推理-动作”结构。这种多维度优化使模型在推理鲁棒性和执行准确性上同步提升。
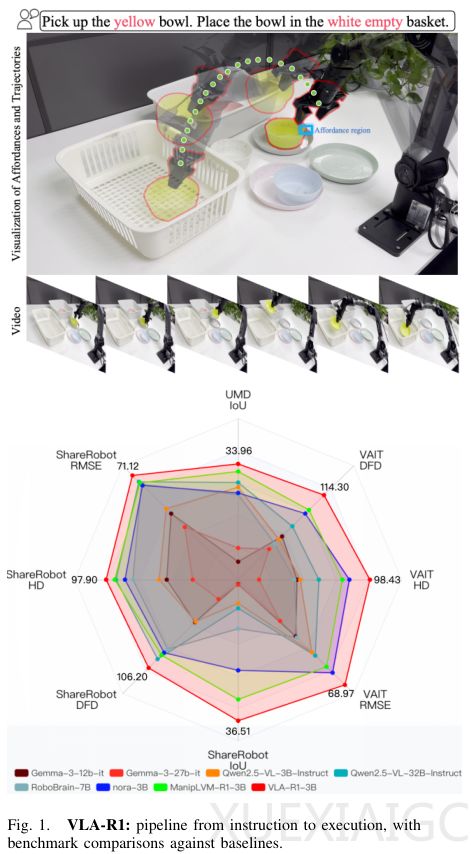
实验验证显示VLA-R1在多个维度显著超越基线模型。在ShareRobot数据集测试中,其定位精度(IoU)达36.51,较同类模型提升17.78%,轨迹误差降低17.25%。领域外泛化测试更凸显模型真正的推理能力——未见过数据的处理表现甚至优于训练数据。模拟环境中,面对随机变化的桌面场景,VLA-R1在轨迹任务成功率高达70%,而基线模型NORA几乎完全失效。真实世界测试进一步证实其可靠性,在存在颜色干扰和物体遮挡情况下仍保持62.5%的感知成功率和75%的动作执行率。
消融研究表明思维链与强化学习具有协同效应:单独使用CoT可使定位精度提升19.5%,结合RL后各项指标实现飞跃。这种组合策略既保留了结构化推理的优势,又能通过精细奖励优化具体动作。当前研究聚焦单臂机器人平台,未来扩展至更复杂系统将推动通用物理智能的发展。该成果证实,模仿人类的渐进式推理是突破机器人环境适应瓶颈的关键路径,为具身智能领域提供了重要的方法论参考。
原文和模型
【原文链接】 阅读原文 [ 3467字 | 14分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


