文章摘要
【关 键 词】 视觉增强、代码辅助、多模态、智能体框架、基准测试
SWE-Vision是一种极简的视觉智能体框架,旨在通过让模型编写并执行Python代码来弥补其在基础视觉任务中的精度缺陷。研究发现,尽管当前多模态大模型在编程能力上已接近资深工程师水平,但在计量、计数、空间关系判断等基础视觉任务中仍频繁出错,其根本问题在于“模型看见了,却无法精确处理”——例如能感知柱状图大致比例却难以准确计算比值,或识别物体后清点数量出错。针对这一现象,UniPat AI提出核心假设:既然模型擅长编程,就应让它用代码这一最熟悉的工具来验证与精炼视觉判断。
该框架仅依赖两个基础工具:`execute_code`(在持久化Jupyter环境中运行Python)与`finish`(输出最终答案),避免引入大量专用视觉API,从而保持接口通用性与简洁性。其控制层采用标准agentic循环,支持最多100轮迭代与高推理努力设置;执行层则通过Docker容器部署持久化ipykernel,确保变量、图像对象与中间结果可在多次调用间保留,并实现安全隔离与复现性。关键设计包括有状态执行环境、图像输入/输出闭环(支持模型生成可视化并自我验证),以及兼容OpenAI函数调用标准,使系统具备即插即用特性。
在实际工作流中,模型首先评估问题是否需计算验证,若需则调用代码进行分析(如用PIL/NumPy/matplotlib处理图像),将数值、报错或可视化结果回传自身,持续迭代直至确认答案。这种机制使模型能像科学家一样分步实验:先读图检查尺寸,再裁剪局部、统计特征、绘制辅助线验证,最后输出结论。与无状态代码执行相比,stateful notebook使多步推理成为同一会话中的连续实验,极大提升复杂任务处理能力。
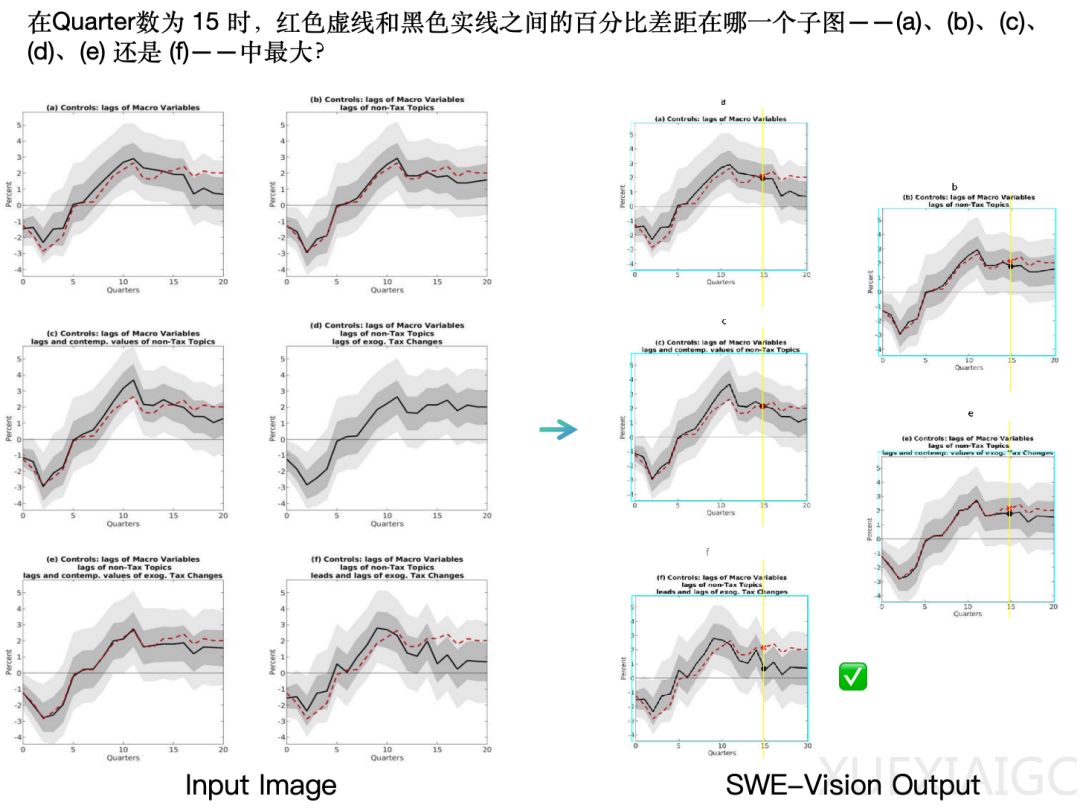
在五个主流视觉基准上,SWE-Vision显著超越现有前沿模型:BabyVision达64.4、MathVision达94.0、Zero-Bench-Sub达50.1、OmniSpatial达69.0、CharXiv-RQ达82.5。值得注意的是,提升幅度最大的并非高阶推理任务,而是基础感知能力,如计数、颜色识别与空间关系判断——这表明代码辅助对弥补模型“直觉式视觉”的细节缺失尤为有效。其成功源于极简设计带来的泛化优势:工具语义与模型已有能力高度一致,支持状态积累与中间结果复检,且不依赖任务特定策略3。
未来方向聚焦于让“代码增强视觉”成为模型原生能力: 需训练模型学会判断调用时机、主动验证中间步骤、失败时切换策略,并最终实现“观察”与“计算”的深度融合。为此,亟需构建含多模态交错智能体轨迹的SFT/RL数据集及交互式训练环境,推动模型从被动应答转向主动感知、行动与反思。SWE-Vision以约五百行代码开源实现,为该路径提供了可复现、轻量化的起点。
原文和模型
【原文链接】 阅读原文 [ 2835字 | 12分钟 ]
【原文作者】 量子位
【摘要模型】 qwen3-vl-plus-2025-12-19
【摘要评分】 ★★★★★


相关文章


