京东卷出新高度!硬刚「复杂指令」长时长、自由态数字人直播终于丝滑了
文章摘要
【关 键 词】 智能体时代、数字人突破、多模态融合、长时生成、实时互动
京东在2026年GTC大会上正式迈入AI智能体应用的新阶段,其核心突破在于解决了长期困扰行业的数字人“躯壳”问题——即如何让AI智能体实现高表现力、长时长、自由态的实时交互。以往数字人受限于文本指令控制弱、多模态信号冲突及身份漂移等难题,难以支撑真实直播场景中的复杂动作与持续连贯性,但京东推出的JoyStreamer与JoyStreamer-Flash两大数字人大模型,显著打破该技术瓶颈。
该模型成功实现了分钟级、自由态、实时互动的数字人生成效果,并在arXiv上发表相关论文,性能全面超越当前SOTA模型。关键能力体现在三方面:一是超强文本控制力,能精准响应复杂指令并驱动全身动作;二是高保真唇形同步,在剧烈运动过程中依然保持口型与音频高度一致;三是稳定身份持久输出,可支持30秒以上长视频生成而无视觉错位或“站桩式”停滞现象。
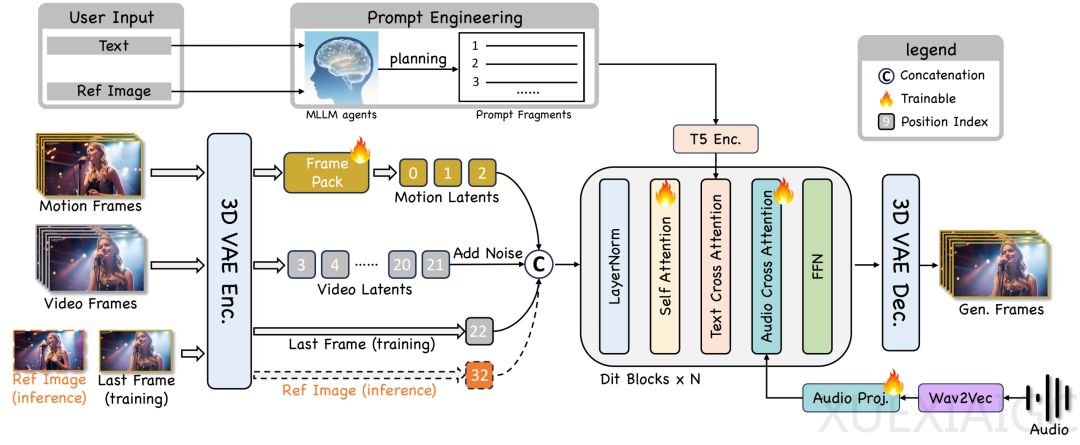
技术上,京东团队创新性采用双教师DMD后训练机制,将音频教师与文本教师协同作用于模型优化中,在不增加额外数据的情况下,提升文本到动作的语义对齐效率。针对文本与音频控制模态之间的冲突问题,提出了“动态CFG调制策略”,使动作框架与唇部细节分别在生成早期与晚期优先执行,实现二者互不干扰。为应对身份漂移难题,设计了历史帧编码模块(FramePack)+伪最后一帧策略,通过引入参考图像锚定机制确保人物一致性。
在推理速度方面,JoyStreamer-Flash版本实现实时流式生成无限时长视频,达到30FPS帧率,并通过CausVid蒸馏、KV缓存加速与多GPU并行推理优化性能。测试表明,其GSB评分高达1.36与1.73,显著优于Omnihuman和KlingAvatar等竞品,证明其在文本遵从、唇形准确度及ID保持等多项指标上的优越性。
落地场景中,京东已将技术应用于自身电商直播体系,服务超7万家商家。尤其强调开放性和普惠性,数字人直播能力免费向中小商家开放,支持一键配置与复刻真人主播功能。新秀丽借助“直播间复刻”能力实现公域流量增长超60%,人均停留近2分钟,验证了其商业转化价值。
更深远的战略意义在于,京东坚持不追逐单纯参数规模,而是以效率、成本与性能平衡为重心推进大模型演进。例如JoyAI-LLM Flash仅480亿参数却仅激活3B算力,任务token消耗仅为竞品五分之一;大量业务反馈形成闭环数据飞轮,反哺模型迭代与实际能力提升。未来目标指向换装能力、跨主播互动及零幻觉生成等更高阶挑战。
京东AI的技术路线选择体现了务实主义哲学,正通过真实产业场景打磨技术,使其从“尝鲜工具”升级为拉动GMV的核心增长引擎。这场基于真实需求驱动的产业突围战,正在由“数字人”的成长所引领。
原文和模型
【原文链接】 阅读原文 [ 3314字 | 14分钟 ]
【原文作者】 机器之心
【摘要模型】 qwen3-vl-flash-2026-01-22
【摘要评分】 ★★★★★


相关文章


