仅用三五条样本击败英伟达,国内首个超少样本具身模型登场,还斩获顶会冠军
文章摘要
【关 键 词】 具身智能、少样本学习、机器人操作、三维建模、知识迁移
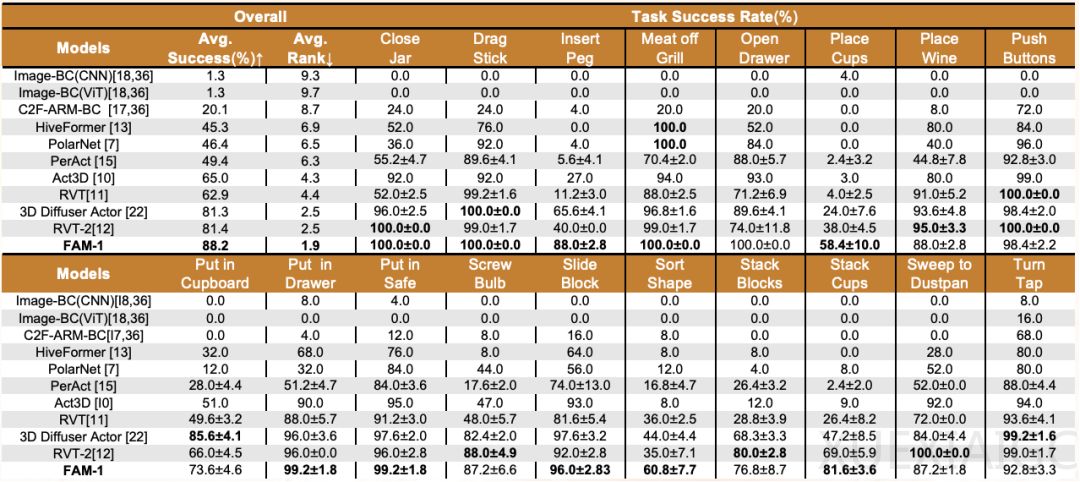
国内首个少样本通用具身操作基础模型FAM-1正式发布,标志着具身智能领域在突破数据稀缺瓶颈方面取得重要进展。该模型由中科第五纪团队开发,基于NeurIPS 2025入选论文《BridgeVLA》的核心架构,首次实现大规模视觉语言模型与三维机器人操作控制的高效知识迁移与空间建模融合。FAM-1仅需3-5条样本数据即可完成精准学习,操作成功率高达97%,全面超越当前国际先进水平。
传统具身智能面临两大核心挑战:真实世界数据采集成本高、规模受限,以及现有视觉-语言-动作模型依赖大规模标注数据弥补泛化不足。为解决这些问题,FAM-1采用BridgeVLA创新框架,通过知识驱动的预训练和三维少样本微调两大模块实现突破。前者构建多维度操作知识库,挖掘视觉语言模型隐含知识;后者利用三维热力图对齐技术,显著提升数据利用效率。这种架构成功将三维结构信息保留率提升80%以上,减少了对暴力拟合数据的依赖。
在国际基准测试中,FAM-1展现出显著优势。在RLBench评测中,其88.2%的操作成功率较RVT-2等模型提升6%以上,特定任务平均成功率提升超30%。真机部署测试更验证了模型的产业化潜力:在干扰物体、光照变化等复杂条件下,基础任务成功率保持97%,挑战任务性能领先对比模型30%以上。这些成果得益于模型对机械臂关键点位置和轨迹的精准预测能力,以及跨场景、跨任务的稳定泛化性能。
该技术的突破性在于将少样本学习与三维空间建模深度结合,使机器人首次具备接近人类的快速适应能力。团队同步公布的EC-Flow技术,进一步展示了从无标注视频中自监督学习的新路径,为降低应用门槛提供可能。中科第五纪计划沿三个方向持续突破:增强基础模型泛化性、拓展工业场景应用、开发导航场景通用模型。
FAM-1的发布标志着具身智能从单点技术向体系化落地转变,为机器人进入工业生产和日常生活奠定基础。其创新架构不仅重新定义了具身大模型标准,更通过知识迁移与三维建模的融合,为突破数据桎梏提供了可复用的技术范式。随着后续EC-Flow等技术的成熟,未来机器人有望通过观察人类行为自主学习,进一步加速智能机器人时代的到来。
原文和模型
【原文链接】 阅读原文 [ 1873字 | 8分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


