仅需15%全量Attention!「RTPurbo」阿里Qwen3长文本推理5倍压缩方案来了
文章摘要
【关 键 词】 大模型、上下文窗口、计算开销、注意力机制、推理加速
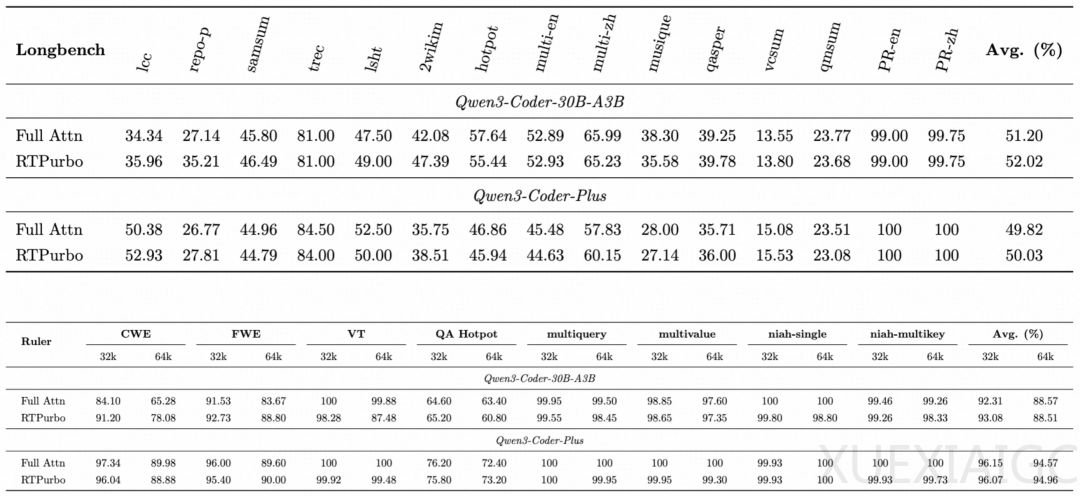
长序列处理已成为大模型应用中最昂贵的资源消耗点。当前主流Full Attention机制下,计算开销随输入长度呈平方级增长,导致长文本处理既昂贵又低效。针对这一核心瓶颈,阿里RTP-LLM团队提出创新性解决方案RTPurbo,通过非侵入式压缩方法实现Attention计算5倍压缩。该技术的关键在于识别LLM内部的长程Attention Head,仅保留15%关键Head的全局信息,其余Head采用局部处理的Sliding Window Attention,在保持模型效果的同时显著降低推理成本。
现有技术路线中,Linear Attention和Sparse Attention虽能优化计算,但存在工程适配复杂、长序列召回能力弱等缺陷。RTPurbo的创新性体现在其Headwise混合算法设计,模拟人类阅读时的信息处理模式:少数Head负责远距离信息召回,多数Head专注局部推理。实验数据显示,仅使用15% Full Attention的方案一,其长文处理能力显著优于保留85% Full Attention的方案二,验证了长序列场景存在可观压缩空间。
为克服压缩带来的性能扰动,团队开发了自蒸馏训练范式。通过让压缩模型对齐原模型输出,仅需1万条32k长度语料即可实现长文任务无损,且避免短文本能力退化。该方法突破性地解决了高质量长文本语料稀缺和RL模型过拟合两大难题。实际测试表明,压缩后的Qwen系列模型在多项长文指标上与原始模型持平,同时完全保留对话、推理等通用能力。
从技术原理看,RTPurbo的设计与大模型可解释性研究发现高度吻合。Softmax在长序列下的熵增特性导致注意力弥散,而LLM天然演化出”局部处理+全局召回”的分工机制。团队通过PTX指令优化、稀疏度感知调度等工程创新,在256k序列下实现单算子9倍加速。这些优化使RTPurbo不仅适用于特定模型,更形成可迁移的通用加速方案。
该研究成果对行业实践具有双重启示:技术上证明注意力机制存在结构化稀疏特性,工程上提供兼顾性能与成本的落地方案。项目已开源模型代码,其采用的Context Parallel等创新架构为大模型推理效率提升开辟新路径。这些进展为突破长上下文窗口的商业化瓶颈提供了重要技术支撑。
原文和模型
【原文链接】 阅读原文 [ 2888字 | 12分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


