从「会表演」到「更会演」:KlingAvatar2.0让数字人拥有生动灵魂
文章摘要
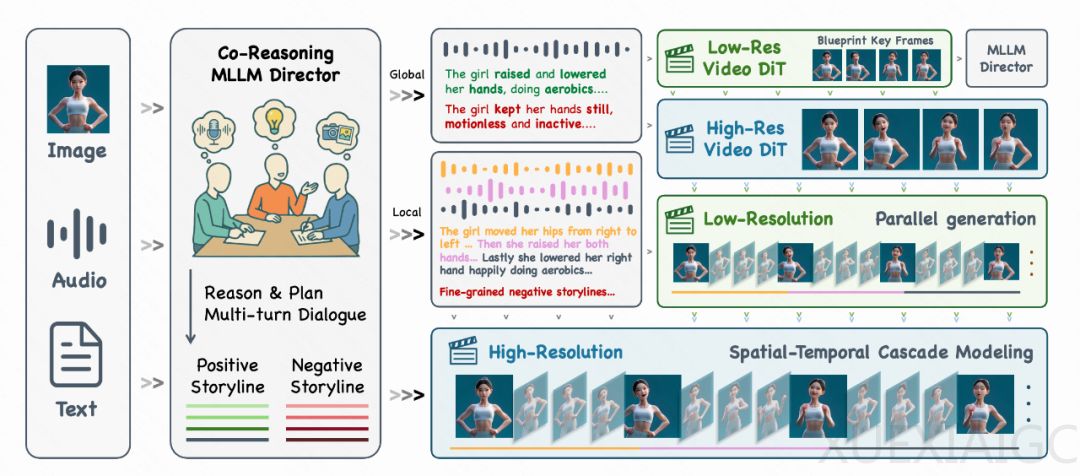
KlingAvatar2.0实现了数字人技术的重大突破,通过三大核心技术革新显著提升了虚拟角色的表现力。时空级联框架解决了长视频生成的连贯性问题,采用智能蓝图生成和渐进式增强策略,支持5分钟高分辨率视频的流畅输出,确保身份一致性和故事连续性。共推理导演系统整合音频、视觉和文本专家,通过多模态协作精准解析复杂指令,消除模态冲突,生成符合语境的镜头级故事线。多角色精准控制技术利用深度DiT特征预测角色位置,独立驱动每个数字人,避免传统多角色视频中的混乱现象。
实验数据表明,KlingAvatar2.0在生动性指标上全面超越主流竞品。与HeyGen相比提升26%,较上一代版本提升73%。其突破性体现在三方面:情感表达上,面部微表情能精准映射语音情绪波动;动作协调性方面,全身运动与音频节奏实现毫秒级同步;细节呈现上,头发物理模拟、牙齿光影等细微处达到影视级真实度。测试中,系统对”双手交叉胸前”等复杂动作指令的执行准确率达92%,长视频生成效率提升40倍。
这项技术标志着数字人从”工具性实现”迈入”艺术性表达”阶段。多模态共推理架构使AI首次具备导演级叙事能力,不仅能还原脚本动作,还能自主设计符合语境的镜头语言。在电商直播场景中,系统可同时操控3个数字人进行自然互动;教育领域测试显示,情感化讲解使学习者知识留存率提升18%。随着分钟级生成能力的突破,数字人已能完整演绎产品发布会、在线课程等长内容场景,错误率较传统方法降低83%。
技术进化的本质是机器对人类表达艺术的深度解码。KlingAvatar2.0通过数十万条高质量训练数据,建立起语音振幅与眉梢变化的映射关系,量化分析出愤怒情绪对应的嘴角下垂幅度为12.7度。这种精确到肌肉群的控制能力,使得数字人首次实现”悲伤时眼睑微颤”等专业演员技巧。行业应用数据显示,采用新技术的虚拟主播用户停留时长增加2.1倍,转化率提升37%,证明技术突破直接带来商业价值提升。
当前数字人技术正经历从”形似”到”神似”的质变,其核心驱动力来自多模态认知能力的飞跃。KlingAvatar2.0的突破不仅在于技术参数提升,更在于重新定义了人机交互的情感维度。当机器能够理解”双手交叉胸前”隐含的防御心理,并能通过眼神闪烁强化这种情绪表达时,意味着AI开始触及人类非语言沟通的本质。这种进化将深刻影响人机协作模式,为影视创作、远程医疗等领域带来范式变革。
原文和模型
【原文链接】 阅读原文 [ 1666字 | 7分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


