从MiniMax到DeepSeek:为何头部大模型都在押注「交错思维」?
文章摘要
【关 键 词】 大模型、交错思维、Agent测试、开源模型、软件开发
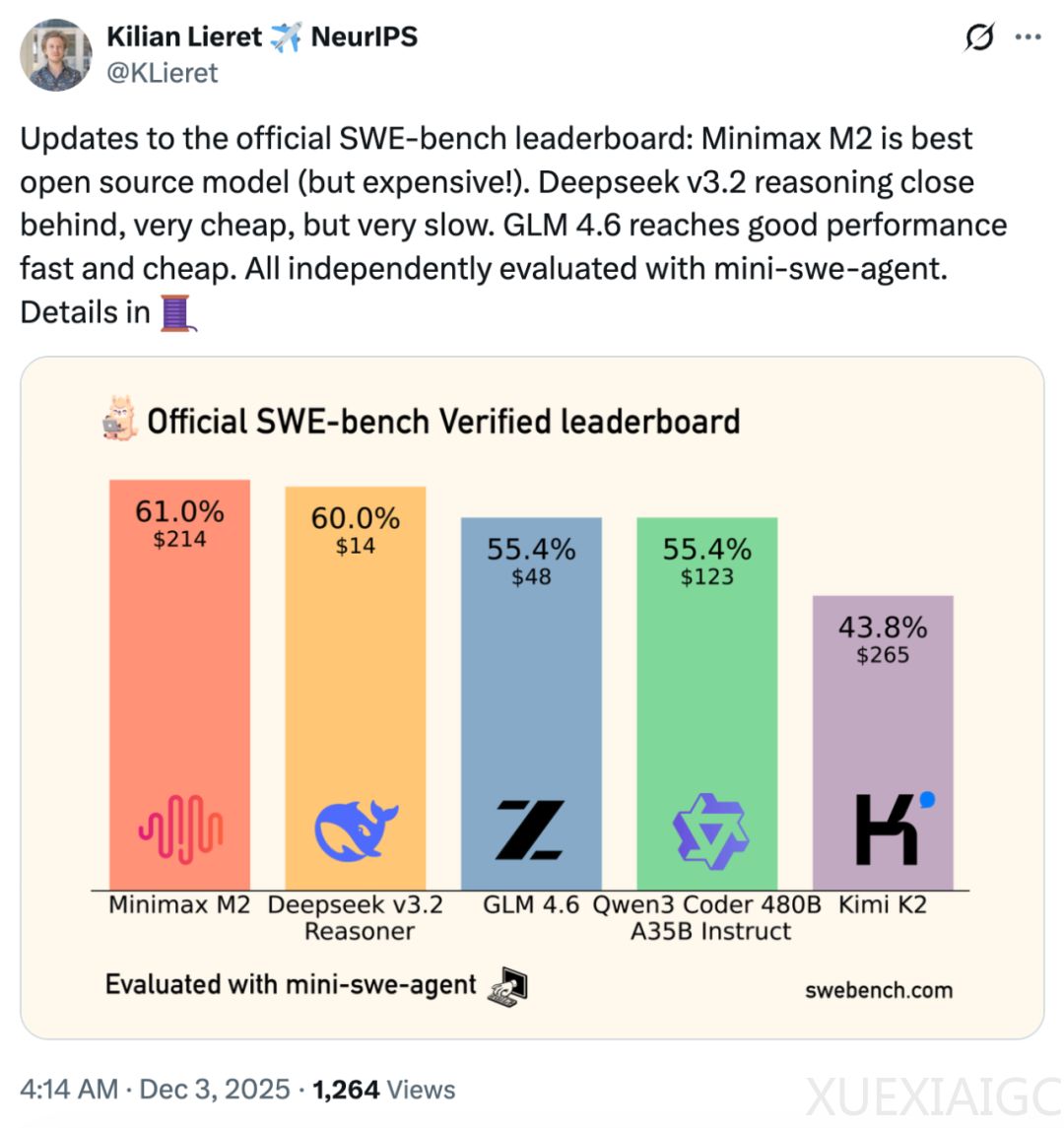
MiniMax新一代大模型M2在轻量级软件工程Agent基准测试mini-SWE-agent中表现最佳,超越了DeepSeek、GLM、Qwen、Kimi等其他竞品。该测试主要评估大模型在真实软件开发任务中的多步推理、环境交互和工程化能力。M2的核心优势在于其采用的「交错思维」(Interleaved Thinking)技术,该技术使模型能够在工具调用过程中持续积累上下文理解,并根据反馈实时调整策略,形成「思考-行动-反思」的闭环。这种机制显著提升了M2在复杂任务中的规划性、执行稳健性和自我纠错能力。
交错思维技术的核心在于将推理与工具调用交替进行,形成动态循环。与传统的线性思维模式(如Chain-of-Thought)不同,交错思维能够在每一步工具交互中保留推理内容,避免「状态漂移」问题。这种技术最早可追溯至2022年普林斯顿大学与谷歌提出的ReAct框架,后经Anthropic的Extended Thinking进一步完善。MiniMax M2通过深度融入这一技术,使其成为模型的「原生思维直觉」,从而在多轮次推理和跨步骤决策中表现更加稳健。
交错思维与普通的大模型记忆技术(如Long Context和RAG)存在本质区别。后者侧重于存储事实性信息,而交错思维则专注于维持动态的思维链状态。例如,在长链路任务中,交错思维能够记住「我为什么要运行这行代码」或「刚才的报错排查到哪一步了」,从而避免逻辑中断。实测数据显示,交错思维在BrowseComp任务中使性能提升40.1%,在Tau²复杂工具调用测试中提升35.9%,甚至在SWE-Bench Verified基准上也有3.3%的增长。
MiniMax M2不仅在性能上表现优异,还具有显著的经济性优势。在包含8步推理和7次工具调用的演示任务中,M2的总成本仅为$0.001669,比同级别的Claude Sonnet便宜近12倍。这种低成本高可见性的组合,为开发者提供了快速迭代的可能性,成为构建复杂工具编排和开发工作流的关键优势。
目前,交错思维技术正加速成为行业共识。除MiniMax外,Kimi K2、Gemini 3 Pro和DeepSeek V3.2等头部模型也纷纷采纳类似技术。MiniMax通过开源项目Mini-Agent和与Kilo Code、OpenRouter等平台的合作,推动交错思维成为可复用的行业标准。社区反馈显示,开发者对这一技术的认可度持续提高,认为其为Agent落地提供了全新的解决思路。
尽管Agent技术仍面临挑战,但交错思维的成熟标志着其迈向生产级阶段的转折点。随着更多厂商和开发者的加入,这一技术有望进一步推动AI Agent在复杂任务中的可靠性和可用性。
原文和模型
【原文链接】 阅读原文 [ 3420字 | 14分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章



