文章摘要
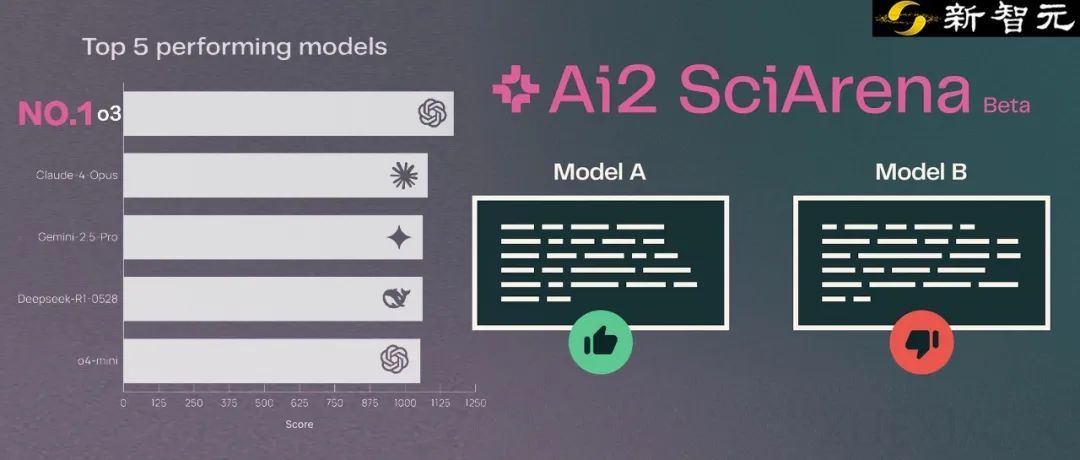
AI大模型在科研领域的应用日益广泛,但如何准确评估其科研能力仍是一个难题。为了解决这一问题,Ai2联合耶鲁大学和纽约大学推出了SciArena,这是一个专为科学文献任务设计的大模型开放式评估平台。SciArena通过引入Chatbot Arena式的众包、匿名、双盲对决机制,使用真实科研问题来测试大模型的表现。目前,已有23个最前沿的大语言模型参与其中,涵盖OpenAI、Anthropic、DeepSeek、Google等巨头的产品。
OpenAI o3在科学任务中表现最为突出,稳居第一,输出的论文讲解更具技术含量。其他模型在不同领域各有优势,例如Claude-4-Opus在医疗健康知识方面表现优异,而DeepSeek-R1-0528在自然科学领域表现抢眼。SciArena的评估流程包括检索论文、调用模型回复、用户评估三个环节,确保检索信息的质量与相关性。平台采用Elo评分系统对各大模型进行动态排名,并提供实时更新的性能评估报告。
SciArena的评估数据来自102位科研专家,他们在四个月内投出了13000多次投票。这些专家均为科研一线的在读研究生,人均手握两篇以上论文,并接受了统一的线上培训,确保评价标准一致。平台的标注数据自我一致性和标注者间一致性均达到较高水平,为评估结果的可信度提供了坚实保障。
尽管SciArena在评估大模型科研能力方面取得了显著进展,但自动评估系统在猜测科研人偏好方面仍表现不佳。表现最好的o3模型准确率仅为65.1%,而其他模型如Gemini-2.5-Flash和LLaMA-4系列的准确率几乎与随机选择相当。相比之下,通用领域的评估模型准确率普遍超过70%,显示出科研任务的复杂性。不过,具备推理能力的模型在判断答案优劣上表现更好,说明推理能力对于理解科研问题本质的重要性。
SciArena-Eval有望成为科研AI评估的新标准,帮助人们更清晰地了解AI是否真正理解科研人的需求。未来,这一平台将继续优化评估机制,推动AI在科研领域的深入应用。
原文和模型
【原文链接】 阅读原文 [ 1548字 | 7分钟 ]
【原文作者】 新智元
【摘要模型】 deepseek-v3
【摘要评分】 ★★★☆☆


相关文章


