刚刚,创智+模思发布开源版Sora2,电影级音视频同步生成,打破闭源技术垄断
文章摘要
【关 键 词】 开源模型、音视频生成、多模态AI、技术创新、国产生态
上海创智学院OpenMOSS团队与模思智能联合发布了中国首个高性能开源音视频生成模型MOVA,实现了真正意义上的”音画同出”。该模型能够生成长达8秒、最高720p分辨率的视听片段,在多语言口型同步和环境音效契合度上展现出极高的工业水准。MOVA选择全栈开源,包括模型权重、训练代码、推理代码和微调方案,填补了音视频生成基础模型的开源空白。
MOVA在物理仿真层面展现了出色的”物理直觉”,声音不仅是音效,而是具备空间感与质感的环境反馈。例如在沙漠中高速掉头的SUV场景中,狂沙飞舞的视觉冲击与马达轰鸣声紧密交织,营造出极强的速度感。这种声画逻辑在复杂的巷战模拟中更为突出,能够精确呈现枪声、子弹掠过声与画面动作的同步。
该模型具备电影级别的口型同步能力,能够根据中英文指令生成与语义、情感高度契合的多人物谈话场景。在公园散步的对话示例中,人物表情、语调变化与口型严丝合缝,告别了传统AI视频的”对口型感”。此外,模型还意外获得了视频文字生成能力,能够在画面中呈现动态文字内容。
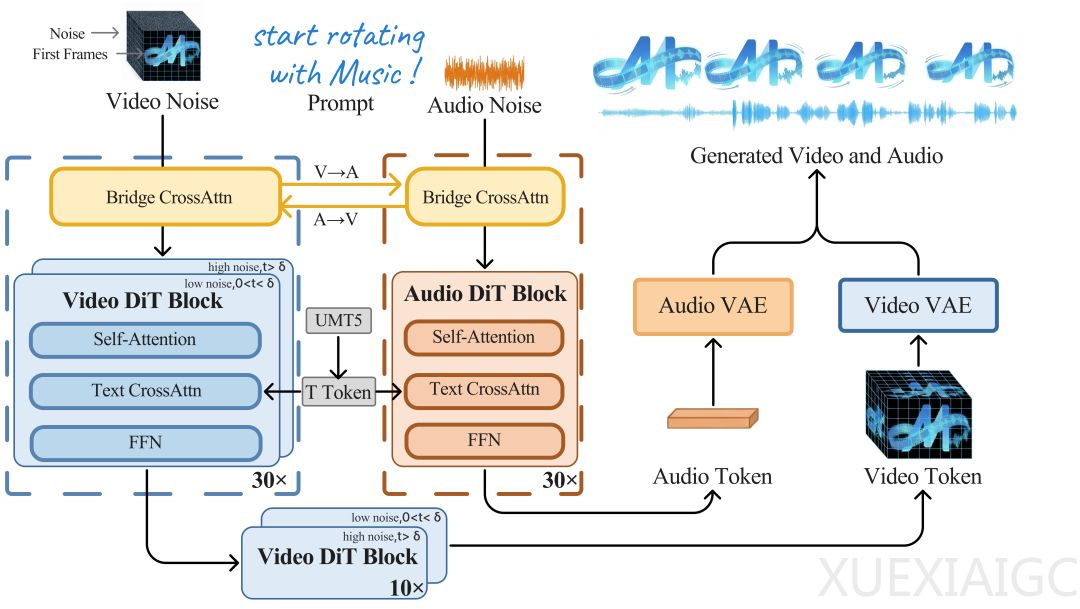
MOVA采用异构双塔与跨模态时间对齐架构,通过14B参数的视频骨干网络和1.3B的音频骨干网络,配合双向桥接模块实现模态融合。团队设计了Aligned ROPE机制解决音视频物理属性差异问题,确保两者在生成过程中的时间同步。数据处理方面构建了三阶段精细化管线,最大限度保留原始数据质量。
训练策略上采用多阶段规模化方法,从360p低分辨率开始专注学习音视频对齐,逐步提升到720p高分辨率精修。创新性地应用Dual Sigma Shift技术,针对音频和视频模态采用不同的噪声偏移,避免隐式模态依赖。推理阶段引入双重CFG机制,允许用户在画质与音画同步间灵活调整权重。
在性能评测中,MOVA展现出明显优势,其口型同步误差(LSE-D)达到7.094,语音准确度指标也领先同类模型。竞技场主观评测中,MOVA的ELO评分达1113.8,面对部分基线模型的胜率超过70%。作为昇腾首个支持的开源多模态音视频生成模型,MOVA的360p版本降低了硬件门槛,使音视频生成技术更易普及。
这一成果体现了上海创智学院”研创学”模式的成效,将学术研究与产业落地深度结合。学生在千卡级规模的工业级基模训练中承担核心任务,积累了稀缺的实战经验。模思智能作为创新出口,持续将前沿理论转化为商用生产力工具,形成了技术研发与商业价值相互促进的良性循环。MOVA的发布不仅补全了中国音视频生成基模的开源版图,也为AGI时代的人才培养提供了新范式。
原文和模型
【原文链接】 阅读原文 [ 6264字 | 26分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


