刚刚,Kimi开源新架构,开始押注线性注意力
文章摘要
【关 键 词】 线性注意力、混合架构、Kimi Delta、长上下文、计算效率
在智能体时代,推理的计算需求成为核心瓶颈,标准注意力机制的低效问题日益凸显。线性注意力虽能降低计算复杂度,但受限于表达能力,在语言建模中表现历来不如softmax注意力。近期通过门控机制和delta规则等创新,线性注意力在中等长度序列上的性能已接近softmax水平,但长序列建模仍存在理论挑战。混合架构成为平衡质量与效率的解决方案,但此前缺乏大规模验证。
月之暗面团队提出的Kimi Linear架构通过Kimi Delta注意力(KDA)实现了突破。KDA采用细粒度的channel-wise门控机制,优化了有限状态RNN内存的使用,并通过DPLR矩阵的专门变体实现定制化分块并行算法,计算量比通用方案减少100%。该架构以3:1比例交错排列KDA与全注意力层,在48B参数的预训练模型中,长上下文任务中可减少75%的KV缓存需求,解码吞吐量提升至全注意力模型的6倍。
技术实现上,KDA通过短卷积和Swish激活处理输入表示,采用每通道衰减的低秩投影,并引入数据依赖的门控机制。混合架构选择层间交替而非头内混合,3:1比例展现出最佳质量-吞吐量权衡。全注意力层采用无位置编码(NoPE)设计,将位置感知功能完全交由KDA处理,既简化了长上下文训练,又提升了推理效率。
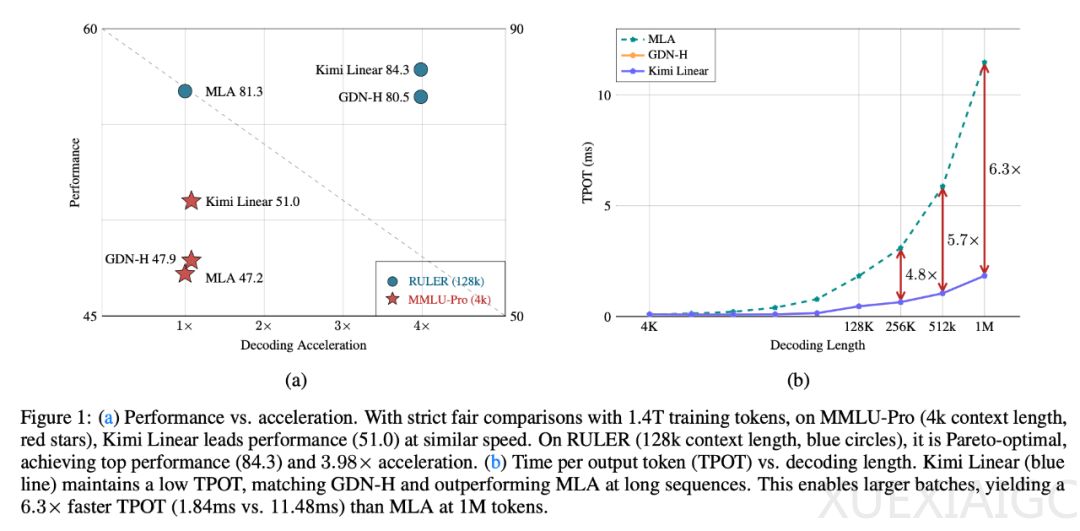
实验结果显示,Kimi Linear在1.4T token预训练中全面超越传统全注意力架构:通用知识任务(MMLU、HellaSwag)、数学推理(GSM8K)和中文任务(CEval)均取得最高分。在128k长上下文评估中,RULER(84.3)和RepoQA(68.5)得分显著领先,平均性能优于基线54.5%。强化学习场景下,数学任务训练准确率增速比全注意力快50%,测试集表现同步提升。
效率方面,1M上下文长度解码速度达全注意力的6倍,且训练阶段的预填充延迟与简单线性注意力相当。消融研究表明,Sigmoid门控优于Swish,卷积层在混合模型中仍具关键作用。缩放定律分析显示,Kimi Linear计算效率比基线高16%,未来通过超参数优化可能进一步提升。
该项目开源了KDA内核并发布两个模型检查点,vLLM已宣布支持该架构。研究者指出,这仅是迈向无限上下文模型的中间阶段,全局注意力仍受解码限制,线性注意力需解决基础设施挑战。行业动态显示,Kimi与Qwen倾向线性注意力路线,而MiniMax坚持全注意力,技术路线分化明显。
原文和模型
【原文链接】 阅读原文 [ 4328字 | 18分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


