华为新开源!扩散语言模型突破32K上下文,还解锁了「慢思考」
文章摘要
【关 键 词】 文本生成、扩散模型、长序列训练、慢思考、华为技术
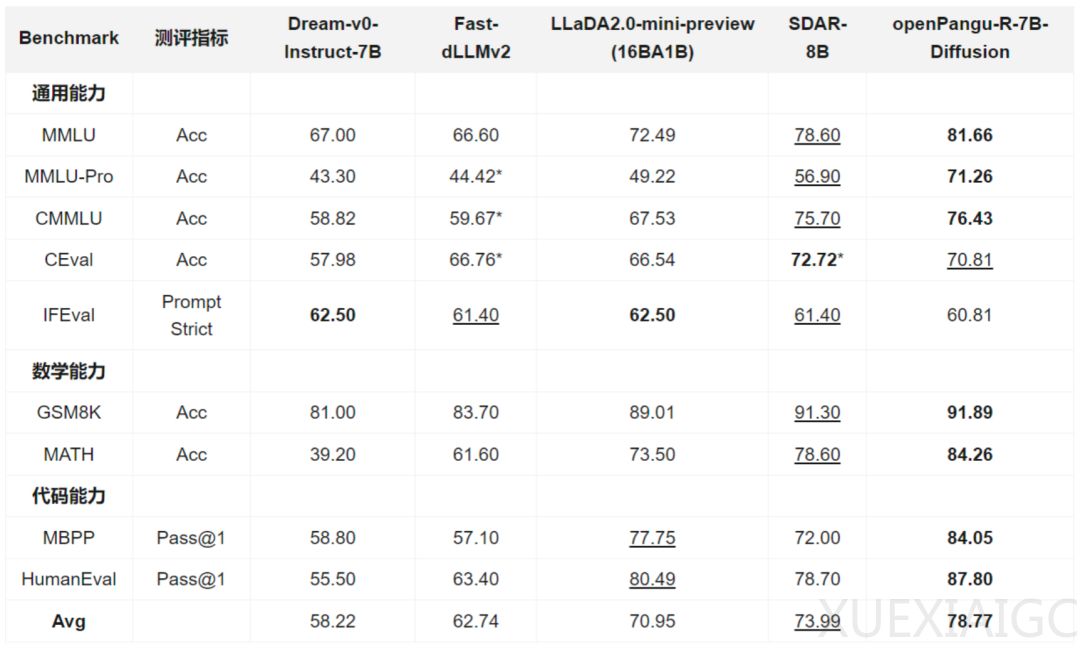
华为发布openPangu-R-7B-Diffusion模型,标志着文本生成领域从自回归向扩散语言模型的重要范式转变。该模型基于openPangu-Embedded-7B进行少量数据续训练,成功将扩散语言模型的上下文长度扩展至32K,解决了长序列训练不稳定的核心痛点。在”慢思考“能力的加持下,模型在多个权威基准测试中创下7B参数量级的新纪录,包括多学科知识、数学推理和代码生成等领域。
架构创新是openPangu-R-7B-Diffusion的核心突破。模型创新性地融合了自回归的前文因果注意力掩码,而非沿用传统扩散模型的全注意力或分块掩码。这一设计从根本上解决了架构适配难题,消除了适配壁垒并最大化兼容性。模型能够自然继承自回归模型的预训练知识,为长窗口训练打下坚实基础。
在训练与推理方面,模型采用了双模式解码策略,实现了效率倍增。通过优化BlockDiffusion的思路,模型实现了Context利用率100%,将无掩码Context部分用于标准的自回归Next Token Prediction训练。这种训练方式赋予模型”自回归+扩散”的双重解码能力,用户可灵活权衡生成质量与速度。在并行解码模式下,其速度最高可达自回归解码的2.5倍。
可视化实测展示了模型独特的”慢思考”生成方式。在处理数学逻辑推理题时,模型在4个生成步数内并行地将多个[MASK]噪声逐步去噪还原为清晰的语义Token。首位的
openPangu-R-7B-Diffusion的发布开启了扩散语言模型的新篇章。它成功证明了扩散模型不仅可以实现快速并行解码,还能处理32K长文与深度思考。值得注意的是,该模型的训练、推理及评测全流程均在昇腾NPU集群上完成,展现了国产算力在前沿扩散语言模型领域的强劲实力。这一突破为处理复杂长文本任务提供了新的解决方案,有望推动文本生成技术的进一步发展。
原文和模型
【原文链接】 阅读原文 [ 1134字 | 5分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★☆☆☆


相关文章


