华为昇腾万卡集群揭秘:如何驯服AI算力「巨兽」?
文章摘要
【关 键 词】 AI算力、集群技术、高可用性、故障恢复、模型训练
AI算力集群已成为支撑现代人工智能发展的核心基础设施,其通过整合上万台计算机形成”算力航空母舰”,解决了大模型训练所需的庞大规模计算需求。面对超大规模集群带来的协同工作、故障容错等世界级难题,华为团队开发了一系列创新技术方案。
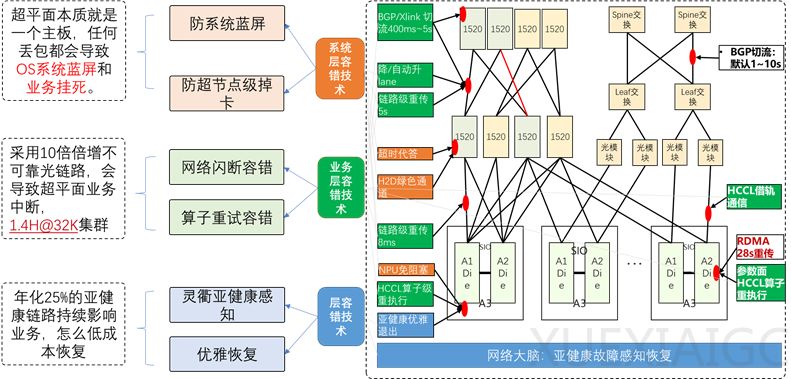
在高可用性设计方面,系统采用三级容错机制确保24小时不间断运行。通过系统层、业务层和运维层的协同容错方案,将故障转化为亚健康状态,实现租户无感知的故障处理。实验数据显示,CloudMatrix 384超节点能有效防止系统级故障,保持业务连续性。
集群线性度优化通过四项关键技术实现近乎完美的算力扩展。拓扑感知协同编排、网存算融合等技术使4K卡集群在训练135B稠密模型时达到96%的线性度,718B稀疏模型在8K卡集群上保持95.05%的线性度,证明大规模计算资源的高效协同能力。
针对训练中断恢复问题,系统采用进程级重调度、在线恢复等创新方法。通过临终检查点传递和故障地址修复技术,将万卡集群的训练恢复时间缩短至30秒内。算子级重试机制则实现网络故障时的秒级恢复,避免训练任务中断造成的资源浪费。
在MoE模型推理领域,三级容错方案有效应对大EP组网架构的可靠性挑战。实例间切换、TOKEN级重试等技术将恢复时间从20分钟降至30-60秒,减卡弹性恢复技术更实现用户无感知的秒级恢复,显著提升推理服务的稳定性。
故障管理系统构建了全栈可观测能力,通过实时监控和诊断技术快速定位硬件问题。网络自诊断和RAS统一框架提升了光链路可靠性,而跨域故障诊断能力则实现对整个集群健康状况的精准把控。
建模仿真平台为算力集群提供”数字化风洞”测试环境。马尔科夫建模技术对训练、推理场景进行多维度仿真,AdaptPack编排优化使PP空泡吞吐提升4.5%-8.24%,通信暴露时间降低89.84%,显著提升资源利用效率。
框架迁移方案通过MSAdapter工具实现PyTorch接口的兼容,覆盖90%以上API。vLLM-MindSpore插件支持大模型一键部署,使盘古72B模型的推理性能获得显著提升。
这些技术创新共同构建起高效、弹性、自愈的算力基础设施体系。未来发展趋势将呈现算法-算力-工程的协同进化,通过异构加速、架构革新和AI运维等手段,持续推动算力基础设施的性能突破和智能化升级。
原文和模型
【原文链接】 阅读原文 [ 3187字 | 13分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


