华为CloudMatrix384超节点很强,但它的「灵魂」在云上
文章摘要
AI领域正进入一个全新的阶段,评估和系统架构的重要性逐渐超越单纯的芯片性能。过去几年,全球科技巨头在AI领域的竞争主要集中在芯片性能的提升上,但随着算力的增强,通信开销成为了新的瓶颈。在大规模分布式训练中,节点间的数据同步问题导致算力利用率大幅下降,AI行业面临深刻的效率危机。为了解决这一问题,华为云推出了CloudMatrix384超节点,旨在构建一个高效的算力网络,彻底消除芯片间的通信瓶颈。
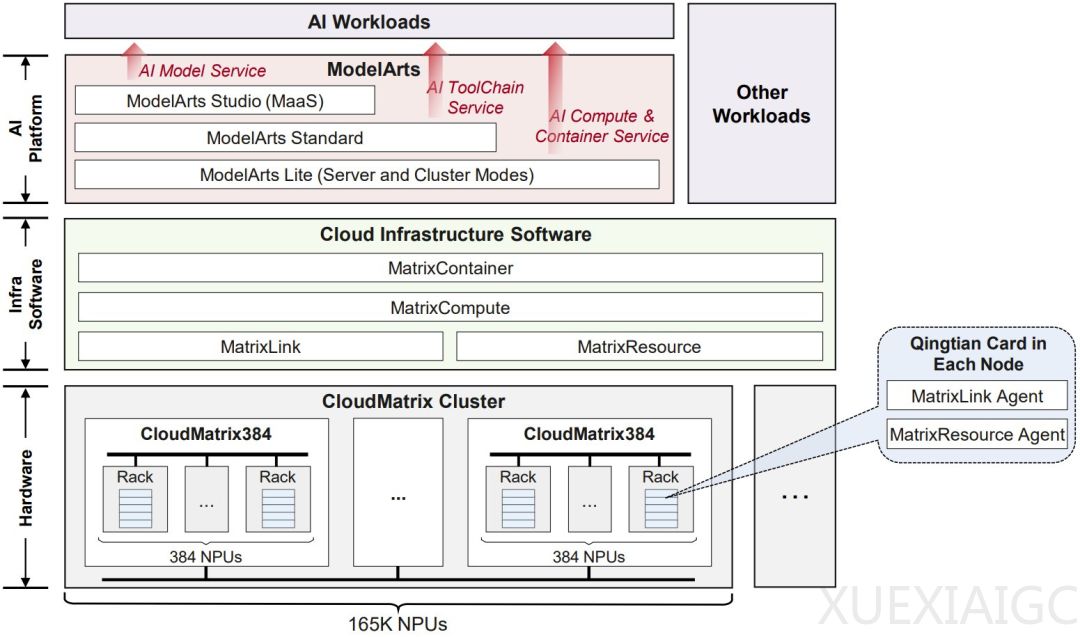
CloudMatrix384是华为云基于下一代AI数据中心架构CloudMatrix构建的,采用了全对等高带宽互联和细粒度资源解耦的设计理念,实现了“一切可池化、一切皆对等、一切可组合”的架构愿景。该超节点配备了384个昇腾NPU和192个鲲鹏CPU,通过统一总线(UB)实现了处理器间的直接、高速通信,显著提升了并行计算的效率。这种架构特别适合现代大模型,尤其是混合专家(MoE)模型,因为它从根本上解决了AI并行计算中的通信瓶颈。
华为云还推出了CloudMatrix-Infer,这是一个全面的LLM推理解决方案,专门为大规模MoE模型优化。它引入了对等式推理架构,将LLM推断系统分解为预填充、解码和缓存三个独立的子系统,并通过高带宽UB互连实现了共享缓存服务。此外,华为还开发了大规模专家并行(LEP)策略,进一步加速了MoE模型的计算效率。
CloudMatrix384的创新不仅体现在硬件架构上,还通过一系列软件优化提升了整体性能。华为云通过智能调度和资源池化,实现了算力的高效利用,将算力利用率提升至85%以上。此外,华为云还提供了灵活的云服务模式,企业可以通过租用CloudMatrix384的一部分算力,降低使用门槛,避免高昂的初始成本和运维负担。
实验表明,CloudMatrix384在处理大规模MoE模型时表现出色。在预填充和解码阶段,其吞吐量和计算效率均超越了业界领先的框架,如NVIDIA H100和H800。华为云还通过INT8量化方案,进一步提升了计算效率和内存利用率,同时保持了模型的准确度。
总的来说,CloudMatrix384代表了下一代AI数据中心的形态,其系统架构和云服务协同能力为AI基础设施的演进提供了新的方向。华为云通过这一创新,不仅解决了当前的算力瓶颈,还为未来的AI发展奠定了坚实的基础。随着技术的不断迭代,CloudMatrix384将继续引领AI基础设施的变革,推动AI应用进入更广阔的领域。
原文和模型
【原文链接】 阅读原文 [ 5494字 | 22分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章


