文章摘要
【关 键 词】 AI技术、大模型、开源社区、微调优化、算力效率
Hugging Face的TRL库与RapidFire AI的集成标志着大模型开发进入超并行时代。单张GPU可同时运行多个微调实验,实验验证速度提升16至24倍,显著降低算力门槛。这一技术融合重构了后训练阶段的工作流,使个人开发者和中小团队能够用消费级显卡完成过去需要集群才能承担的超参数搜索任务。
当前大模型开发重心已从预训练转向后训练阶段,包括监督微调、直接偏好优化和群组相对策略优化等。这些任务对精细化操作要求极高,超参数选择直接影响模型性能。学习率设定、LoRA秩选择、批次大小与梯度累积步数组合等变量构成了巨大的搜索空间。传统串行试错模式反馈周期长,一天仅能验证3到4个想法,迫使开发者依赖直觉而非科学实验。
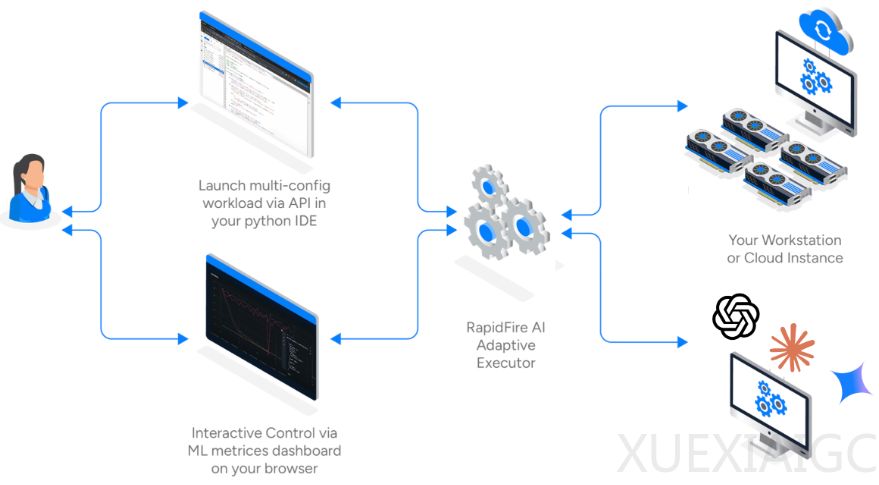
RapidFire AI的核心创新在于自适应分块调度技术。它将数据集切分为微小块,在单GPU上并发推进多个实验配置,几分钟内即可获得早期性能信号。表现不佳的配置可被快速终止,释放算力给更有潜力的实验。高效的共享内存机制使GPU计算单元利用率从60%提升至95%以上,特别适合参数高效微调场景。基座模型权重驻留显存,仅切换LoRA Adapter等小参数量组件,极大降低了切换延迟。
交互式控制操作是另一项突破性功能。开发者可实时监控仪表盘,动态克隆修改实验配置,实现人在回路的优化过程。这种能力解决了传统超参数优化工具依赖集群假设的局限,使有限硬件资源发挥最大效能。官方测试显示,在单张A100上,传统模式需要120-240分钟的任务,RapidFire AI仅需7-12分钟即可获得初步结果。
此次集成深度结合了TRL库的算法优势与RapidFire AI的工程创新。用户几乎无需修改代码即可从串行模式切换为超并行实验,显著提升认知迭代速度。对于GRPO等复杂算法,开发者可同步测试不同组大小的配置,快速识别最佳参数组合。这种能力在数学推理、代码生成等可验证性任务中尤为重要。
技术民主化是此次集成的深层意义。它使消费级显卡用户能够像拥有专业集群的团队一样进行科学实验,有望激发开源社区创新活力。未来,这项技术还可能扩展至RAG系统评估和Agent环境优化等领域,推动AI开发工具链向更精细化、自动化方向发展。开发者现在可以在单卡上高效验证多种微调策略,标志着大模型开发从经验驱动转向数据驱动的科学实验新阶段。
原文和模型
【原文链接】 阅读原文 [ 3287字 | 14分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


