文章摘要
【关 键 词】 AI模型、开源技术、成本效益、数学竞赛、微博生态
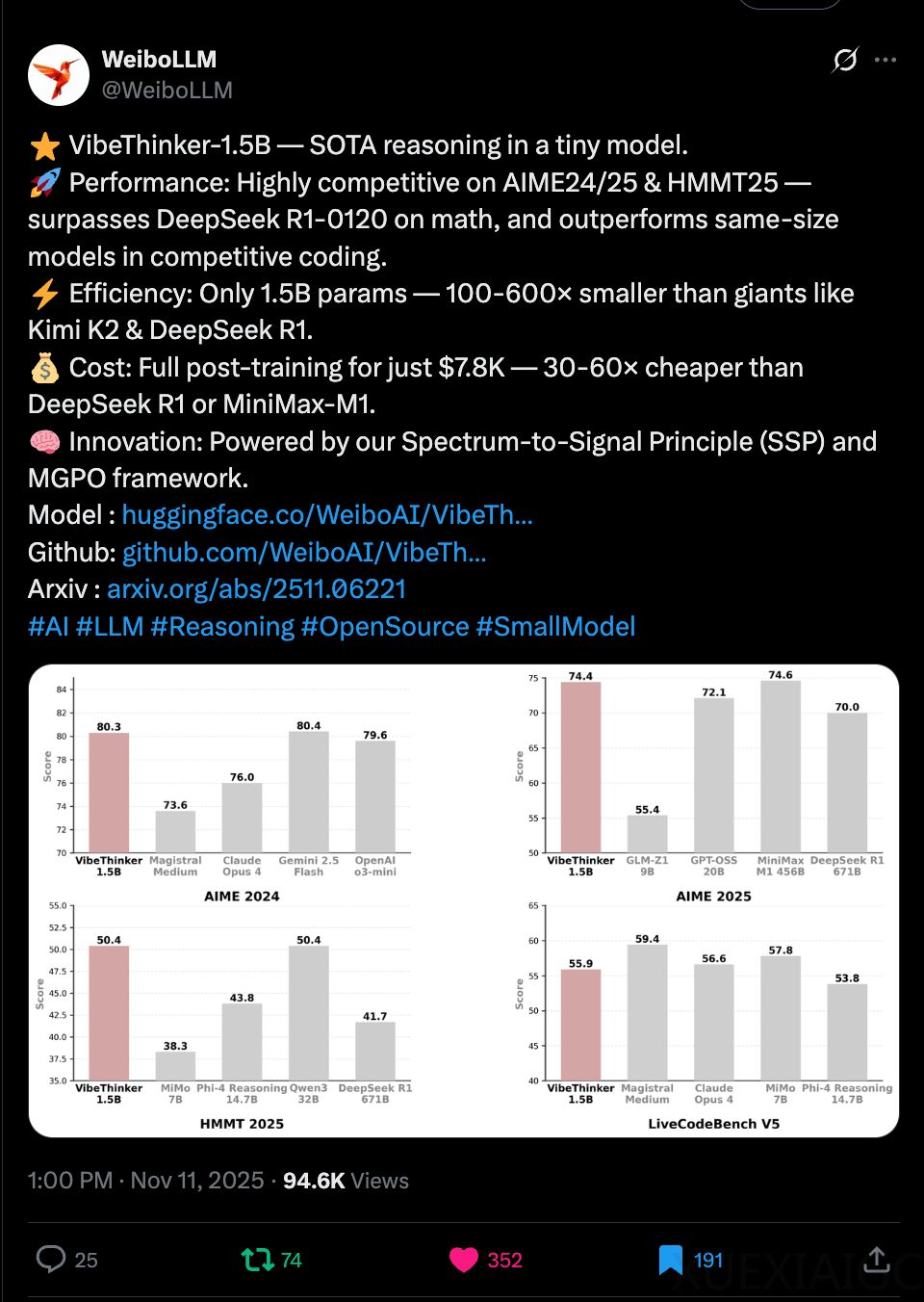
微博AI近日发布的自研开源大模型VibeThinker,以15亿参数的轻量级架构,在国际顶级数学竞赛基准测试中击败了参数量高达6710亿的DeepSeek R1模型,颠覆了行业对“参数规模决定模型能力”的传统认知。该模型采用创新的“频谱到信号原理”(SSP)训练方法,在AIME24、AIME25等数学测试集及LiveCodeBench编程算法题中表现优异,性能接近或超越参数量数百倍的巨型模型,包括Gemini 2.5 flash和Claude Opus 4。
成本控制成为VibeThinker的另一大突破。其单次后训练成本仅7800美元,较行业主流模型的数十万美元降低30-60倍。这一成果源于对计算资源的极致优化——仅消耗3900个GPU小时,而同类训练通常需数万小时。低成本技术路径使得中小机构也能参与前沿AI开发,有望推动行业从“资本密集型”向“效率驱动型”转变。
微博正将这一技术优势转化为生态竞争力。基于自研的“知微”大模型,平台已推出月活超5000万的微博智搜和粉丝近200万的AI评论助手“评论罗伯特”。VibeThinker的加入将进一步强化微博在垂直场景的数据赋能能力,特别是在心理分析和社交互动领域。未来,该模型或深度集成至智能搜索、实时交互等核心功能,通过降低算力消耗释放更多创新空间。
这一技术突破不仅验证了小模型通过算法优化实现复杂推理的可能性,更揭示了AI产业发展的新方向:当规模竞赛触及天花板时,训练策略创新和成本控制将成为下一代竞争焦点。微博通过开源策略加速技术扩散,其构建的“轻量高效+场景深耕”模式,或为行业提供可复用的发展范式。
原文和模型
【原文链接】 阅读原文 [ 1917字 | 8分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★☆☆


相关文章


