文章摘要
【关 键 词】 视频生成、多人交互、AIGC、开源模型、音频驱动
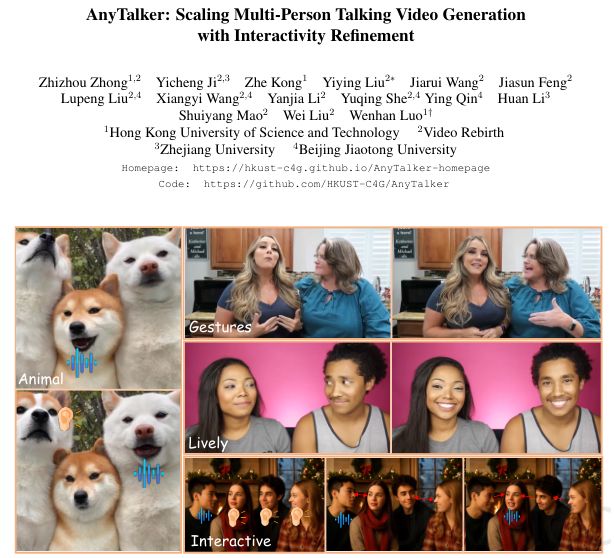
AnyTalker框架通过创新的音频-人脸交叉注意力机制(AFCA)和两阶段训练策略,实现了高质量、可扩展的多人对话视频生成。该技术由香港科技大学、浙江大学等机构联合开源,仅需极少量多人对话数据即可生成具有自然眼神交流和即时反馈的视频,显著降低了对大规模昂贵数据集的依赖。视频生成技术正从单体向群体演变,而AnyTalker解决了现有方案在多人场景中难以处理多音频流或缺乏自然互动的核心痛点。
AFCA模块采用递归调用的循环系统,不预设身份数量,实现了音频与人脸的动态耦合。该模块通过3D VAE、T5编码器和Wav2Vec2模型分别处理视频、文本和音频特征,并引入CLIP图像编码器确保身份一致性。在注意力计算中,音频令牌与人脸令牌深度融合,通过时间注意力掩码实现精准同步。全局面部掩码的运用有效防止画面崩坏,而共享参数的AFCA设计赋予模型无限的身份扩展能力。
研究团队创新性地利用单人数据学习多人模式,通过两阶段训练策略突破数据瓶颈。第一阶段使用1000小时单人视频,通过水平拼接模拟双人场景,建立多流信号的空间对应关系;第二阶段仅用12小时真实多人数据进行微调,却使模型展现出处理三人以上场景的泛化能力。严格的过滤管线确保数据质量,包含珍贵的交互信息如眼神注视和非语言反馈。
团队构建了InteractiveEyes基准数据集和以眼部为中心的交互性指标,填补了多人视频评估的空白。该指标通过追踪倾听阶段的眼部运动轨迹量化互动活跃度,避免了传统指标对互动要素的忽视。实验显示AnyTalker-14B的Interactivity得分达1.01,远超同类方法,生成的角色展现出更自然的响应行为。
性能测试表明,AnyTalker在单人和多人场景均表现卓越。其1.3B版本在标准基准测试中口型同步率优于同类模型,14B版本在交互性上实现质的飞跃。消融实验证实AFCA机制和两阶段训练策略的关键作用——尽管微调会轻微影响口型同步,但交互性得分从0.71提升至0.97,显著改善用户体验。这项技术为数字媒体、播客制作等领域提供了高效的多人生成解决方案。
原文和模型
【原文链接】 阅读原文 [ 3121字 | 13分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


