大模型SFT后效果≠RL潜力!港科大、阿里提出自适应冷启动新范式
文章摘要
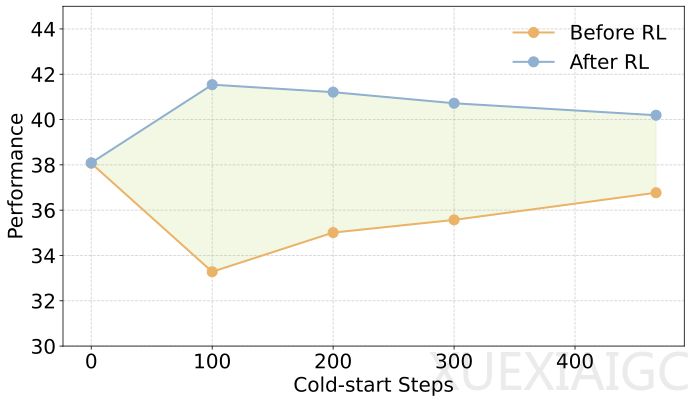
近年来,强化学习逐步确立为大语言模型后训练的核心领域。虽然有大量实证表明该路径能有效激发模型的复杂推理能力,但在实际操作中直接把普通模型投入使用极易迷失探索方向。目前行业通行的应对策略是先利用少量数据进行预前的监督微调训练。然而近期一项重要成果指出这种做法存在严重的误导风险,研究团队深入分析了数据反馈,发现了一个值得警惕的现象,即在早期的冷启动筛选中得到最佳指标的检查点实际上可能并不对应模型最终的强化学习潜力。
这种现象的根本原因在于单纯的微调目标是拟合展示的数据结构,而如果未能妥善控制训练深度,微小的演示数据很容易诱导模型形成机械记忆而非真正的逻辑掌握。随着步骤的增加,模型因过度追求准确率会导致原本具备的广阔探索空间急剧缩小,致使后续算法在进行全局优化时丧失关键的多样性支持。为了突破这一瓶颈,相关科研团队重新审视了训练目标与停止条件,主张不应只以数值表现作为评价唯一标准,而是要同时兼顾输出的熵值等指标。
基于这一洞察,研究提出了具备高度灵活性的自适应早停损失函数,旨在解决冷启动阶段的过拟合风险。该项技术方案通过在 Token 级别与子序列级别分别实施动态监管来达成精细化控制:一旦判定当前位置的预测置信度已处于高位,模块便会自动调低梯度下降的力度以避免重复学习已熟知的信息,而对于尚未确定的区域则继续给予高强度的引导。这种方法使得模型在掌握长思维链等基础规范时,并未丢失原有的泛化基因,保持了生成内容的丰富度和可塑性。此外,为了验证方法的普适性,研究人员在不同的算力配置和多类型数据集上进行了全方位的压力测试。在AIME等数学竞赛题库中的比对数据充分说明,使用该技术的组合策略无论面对何种难度的数据切分均可显著优于现有主流方案并保持性能稳定。此项工作不仅在理论上纠正了对前序阶段效能的误判,也为构建更加强大的自主智能系统奠定了一个切实可行的实施标准,未来有望成为标准化流程中的重要组件被广泛应用。
原文和模型
【原文链接】 阅读原文 [ 2442字 | 10分钟 ]
【原文作者】 机器之心
【摘要模型】 qwen3.5-flash-2026-02-23
【摘要评分】 ★★★☆☆


相关文章


