文章摘要
【关 键 词】 强化学习、奖励模型、策略判别、大语言模型、泛化能力
强化学习已成为推动人工智能向通用人工智能(AGI)发展的关键技术节点,但奖励模型的设计与训练一直是制约模型能力提升的瓶颈。当前,大语言模型通过Next Token Prediction和Test-time Scaling两种范式实现了能力的持续跃升,而奖励模型却缺乏系统性的预训练和扩展方法,导致其能力难以随计算量增长而提升。上海人工智能实验室的研究团队提出了一种新的奖励建模范式——策略判别学习(POLAR),通过解耦绝对偏好,使奖励模型具备可扩展性和强泛化能力。
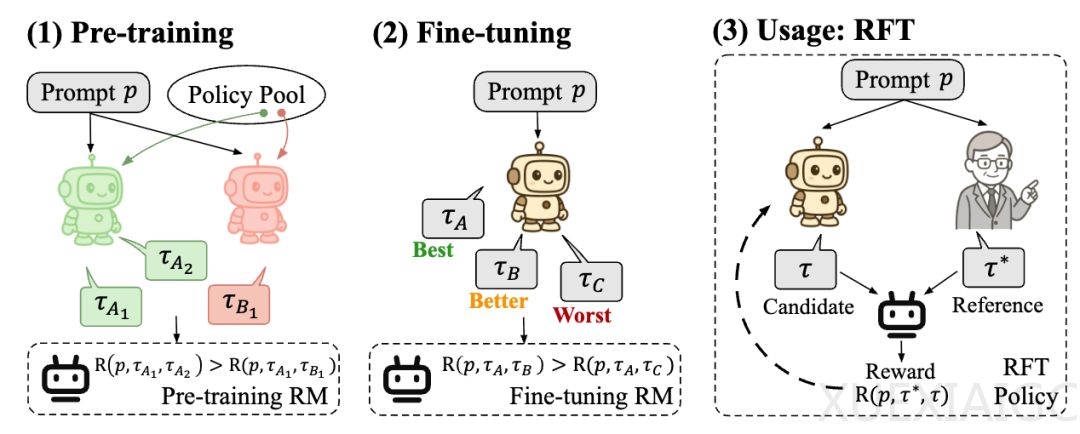
POLAR的核心创新在于其能够基于参考答案为模型输出打分,从而灵活适配多样化的定制需求。与传统奖励模型的“绝对偏好”不同,POLAR只需根据不同的参考回复即可为不同风格的答案生成偏序关系,无需重新训练模型。例如,在回答“彩虹的形成”这一开放问题时,POLAR可以根据用户偏好的风格(简短扼要、详细分析或俏皮发散)为不同回答打分。对于闭式问题,POLAR也能提供比传统二元奖励更细粒度的偏好区分,例如在数学问题中区分答案正确但思路错误的回答。
POLAR的训练方法借鉴了大语言模型的成功经验,通过对比学习建模策略分布的距离。研究人员使用同一策略模型采样的结果作为正例,不同策略模型采样的结果作为负例,从而构建了一种无偏的信号。预训练阶段使用了自动化合成的数据,从131个Base LLM和53个Chat LLM中随机采样模型生成轨迹。这种设计使得POLAR能够隐式建模策略分布的差异和距离,摆脱了对人工标注偏好数据的依赖。
实验结果表明,POLAR展现出了显著的扩展效应。验证集损失随模型参数和计算量的增加呈幂律关系下降,拟合的R²值分别达到0.9886和0.9912,表明分配更多计算资源将持续提升POLAR的性能。在偏好评估实验中,POLAR-1.8B和POLAR-7B在STEM任务中分别超越最佳基线24.9和26.2个百分点,且1.8B参数的模型性能与参数量为其15-40倍的基线模型相当。在强化微调实验中,使用POLAR-7B微调的模型在所有基准测试中平均提升9.0%,显著优于现有开源奖励模型。
POLAR的成功在于其将奖励建模从特定场景的标注偏好中解放出来,通过预训练学习策略间的距离度量,仅需少量偏好样本即可对齐人类偏好。这种方法不仅解决了传统奖励模型的扩展难题,还为强化学习的广泛应用提供了新的可能性。POLAR的推出标志着奖励模型设计范式的重大转变,有望成为推动大语言模型后训练发展的关键技术。
原文和模型
【原文链接】 阅读原文 [ 3180字 | 13分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


