文章摘要
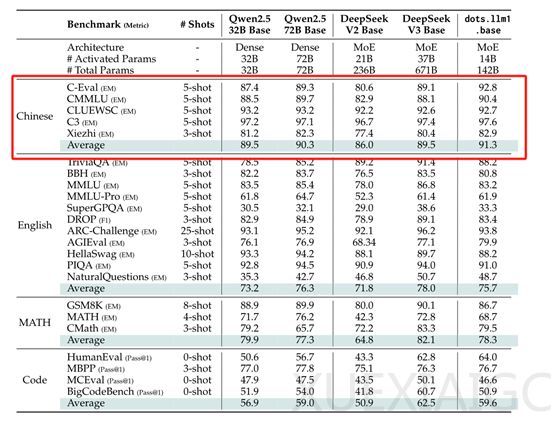
小红书近期开源了其首个大模型dots.llm1,这是一个1420亿参数的专家混合模型(MoE),在推理过程中仅激活140亿参数,显著降低了训练和推理成本。dots.llm1的最大特色在于其使用了11.2万亿token的非合成高质量训练数据,这在当前开源大模型中极为罕见。在中文测试中,dots.llm1以91.3的平均分超越了DeepSeek的V2、V3以及阿里的Qwen2.5 32B和72B,展现了其强大的性能。
dots.llm1采用了单向解码器Transformer架构,但将前馈网络替换为MoE。传统的Transformer架构在处理大规模数据时会消耗巨大的算力,而MoE通过将模型分为多个专家网络,动态选择一小部分专家网络进行计算,极大地减少了算力需求。dots.llm1的MoE由128个路由专家和2个共享专家组成,每个专家网络使用SwiGLU激活函数,能够更好地捕捉数据中的复杂关系。在处理每个输入标记时,dots.llm1会通过路由机制选择6个最相关的专家网络,加上2个共享专家,总共激活8个专家网络。
在注意力层,dots.llm1采用了经典的多头注意力机制(MHA),并引入了RMSNorm归一化操作。RMSNorm通过计算输入的均方根值进行归一化,避免了输入值过大或过小对模型训练的影响,提高了模型的稳定性和性能。此外,dots.llm1在MoE模块中引入了无辅助损失的负载平衡策略,通过动态调整偏置项,确保所有专家网络的负载相对平衡,解决了负载不平衡的问题。
在训练过程中,dots.llm1采用了AdamW优化器,通过引入权重衰减防止模型过拟合,并采用梯度裁剪技术避免梯度爆炸。dots.llm1的训练数据达到了11.2万亿token,通过三级数据处理流水线筛选出高质量语料。第一阶段的文档准备通过URL过滤、正文提取、语言检测和去重等方法,确保数据的纯净性和多样性。第二阶段的规则处理通过行级去重、启发式过滤和模糊去重,剔除了约30%的低质内容。第三阶段的模型处理通过分类器和网页杂波去除模型,进一步提升了数据的质量。
为了促进学术研究,小红书还开源了每1万亿token的中间训练检查点,为大模型的学习动态提供了宝贵的见解。通过TxT360数据集的对比实验验证,dots.llm1处理后的网页数据在MMLU、TriviaQA等基准测试中表现优于当前SOTA开源数据,展现了其在数据处理和模型优化方面的卓越能力。
原文和模型
【原文链接】 阅读原文 [ 1504字 | 7分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-v3
【摘要评分】 ★★★☆☆


相关文章


