文章摘要
【关 键 词】 音视频生成、开源模型、单流架构、视听同步、高效推理
daVinci-MagiHuman是由上海创智学院(SII)生成式人工智能研究实验室(GAIR)与Sand.ai联合发布的开源音视频生成基础模型,旨在解决当前开源生态中生成质量、多语言支持与推理效率之间的平衡难题。该系统采用极简的单流Transformer架构,仅需2秒即可在1张H100显卡上生成5秒高精度音视频同步内容,显著优于传统多流方案。
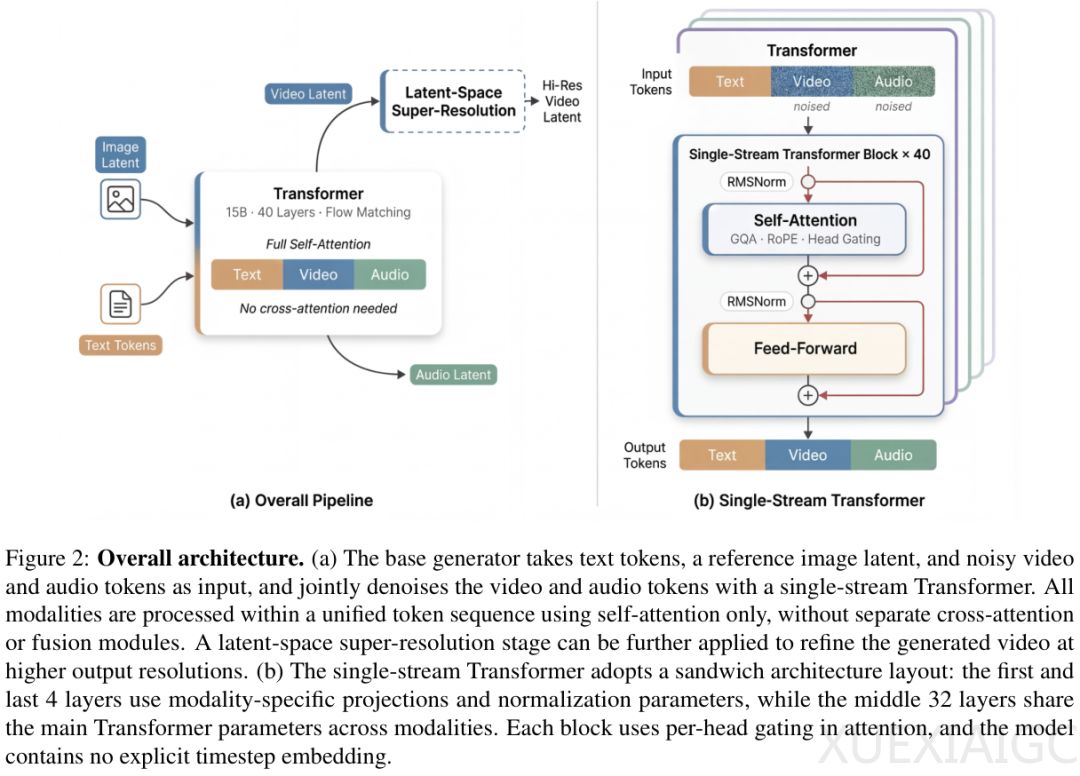
<强>其核心创新在于彻底摒弃跨模块交织设计,将文本、视频和音频Token统一嵌入共享权重的序列中,全部通过自注意力机制实现端到端联合去噪。这一设计避免了独立交叉注意力模块与外挂融合组件,使嘴唇动作与发音在底层自然对齐,无需额外协调。>
<强>模型结构上,40层网络采用三明治式分层策略:首尾4层专用于模态边界处理,核心32层实现深度多模态融合;同时移除显式时间步嵌入,让网络自发推断去噪状态,并引入逐头门控机制增强数值稳定性与表达能力。条件注入被压缩至同一潜变量空间,支持纯文本或静态图像驱动的口型动画生成,消解任务特化模块依赖。>
<强>在视听交融层面,系统强化人形角色的自然表现力,实现情感微表情与肢体律动的语义同步;支持中文普通话、粤语、英文、日文等七种语言的精准发音还原,且具备向更多语种扩展的能力。超分辨率阶段全程维持潜空间操作,利用三线性插值与局部注意力控制开销,在保证画面清晰的同时,持续绑定音频信息以确保唇形匹配精度。>
<强>极致提速方面,模型结合轻量涡轮解码器、全图PyTorch编译器融合算子及DMD-2蒸馏技术,大幅降低推理延迟;基础256p生成仅耗时1.6秒,整套流程总时长为2秒;提升至1080p最高画质时,全流程用时亦控制在38.4秒内。所有测试均基于1张H100显卡完成,展现优异的硬件适配性与工程可行性。>
<强>性能对比显示,daVinci-MagiHuman在VideoScore2视觉评分与文本对齐指标上分别取得4.80与4.18的最优成绩;语音清晰度以14.60%词错误率远超其他开源模型;人类盲测胜率达80%,显著超越Ovi 1.1与LTX 2.3。该成果为开源社区提供了一个兼具速度、质量与可扩展性的通用创作底座,推动音视频生成进入新阶段。>
原文和模型
【原文链接】 阅读原文 [ 3133字 | 13分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 qwen3-vl-flash-2026-01-22
【摘要评分】 ★★★★★


相关文章


