文章摘要
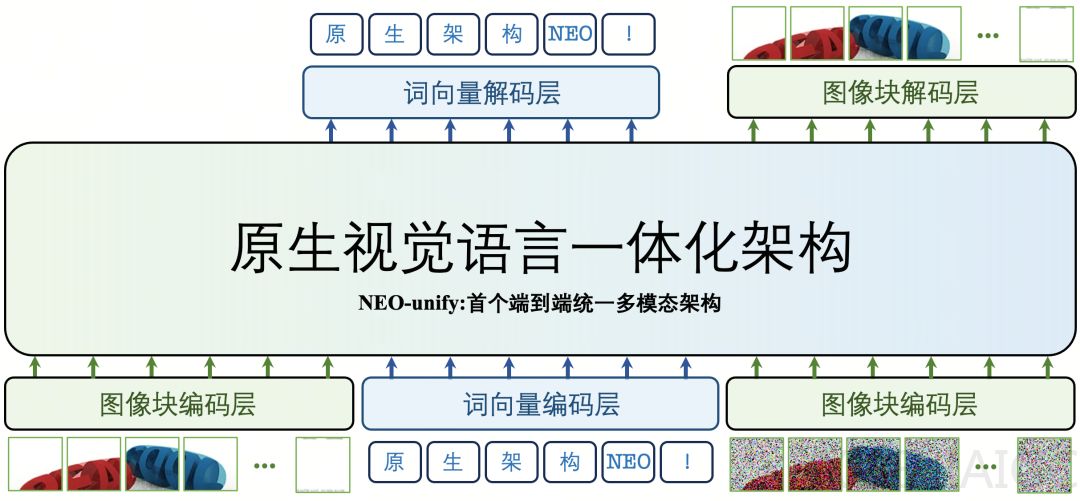
当前多模态大模型领域长期遵循搭配视觉编码器负责感知理解、变分自编码器完成内容生成的默认范式,这种设计在感知与生成之间留下天然鸿沟,后续业界提出的共享编码器折衷方案,也陷入新的结构性设计权衡。基于回归第一性原理的思考,商汤科技联合南洋理工大学发布全新原生、统一、端到端多模态模型架构NEO-unify。该架构彻底砍掉了长期以来行业依赖的视觉编码器和变分自编码器,不再通过组件拼凑实现感知与生成,直接以近乎无损的像素和文字作为原生输入,通过创新的混合变换器(MoT)架构,在同一个体系内打通了视觉与语言的理解+生成双向能力,具备无编码器设计摆脱预训练先验与规模定律瓶颈、MoT实现视觉语言深度融合、提升数据与算力利用效率同时保持高保真细节恢复的特点。
多项技术验证获得关键发现,首先无编码器设计能够同时保留抽象语义与细粒度表征:2B参数的NEO-unify经过9万步初步预训练,在MS COCO 2017上取得31.56 PSNR和0.85 SSIM的成绩,证明即使不依赖预训练视觉编码器或变分自编码器,近似无损的原生输入仍可同时支持高质量语义理解与像素级细节保真;即使冻结理解分支,模型依然可以完成高质量图像重建,具备出色的图像编辑能力,经过6万步初步混合训练,在ImgEdit基准上取得3.32的成绩,还可显著减少输入图像令牌数量。其次无编码器架构与MoT主干高度协同,大幅降低内在冲突,联合训练过程中,理解能力可保持稳定,生成能力收敛速度快,二者协同提升,整体冲突极小。此外无编码器架构展现更高数据训练效率,与Bagel模型相比,该架构使用更少训练token即可取得更优性能。
该架构的推出标志着多模态AI正在从“模态连接”进化为“原生统一智能体”,其无编码器、端到端、多模态统一学习的新路径,为未来实现跨模态认知与生成一体化的智能系统奠定了基础,预示多模态智能正从组件堆叠迈向本质统一,勾勒出通往下一代智能形态的清晰路径,最终可实现原生跨模态思考,构建从未被割裂的高度集成统一智能体,让所需能力从内部自然涌现。目前相关研发工作处于规模化扩张与持续迭代阶段,一系列基于该架构的模型成果与开源贡献,将在近期陆续发布。
原文和模型
【原文链接】 阅读原文 [ 1800字 | 8分钟 ]
【原文作者】 量子位
【摘要模型】 doubao-seed-2-0-lite-260215
【摘要评分】 ★★☆☆☆


相关文章


