微软等提出「模型链」新范式,与Transformer性能相当,扩展性灵活性更好
文章摘要
【关 键 词】 大模型、Transformer、表征链、模型链、弹性推理
随着大语言模型(LLM)的快速发展,扩展Transformer架构已成为推动人工智能领域进步的关键途径。然而,LLM参数规模的指数级增长带来了高昂的训练成本和推理效率问题。为了解决这些挑战,来自微软、复旦大学、浙江大学和上海科技大学的研究者提出了一种名为“表征链”(Chain-of-Representation, CoR)的新概念,旨在通过多尺度特征转换提升模型的灵活性和可扩展性。
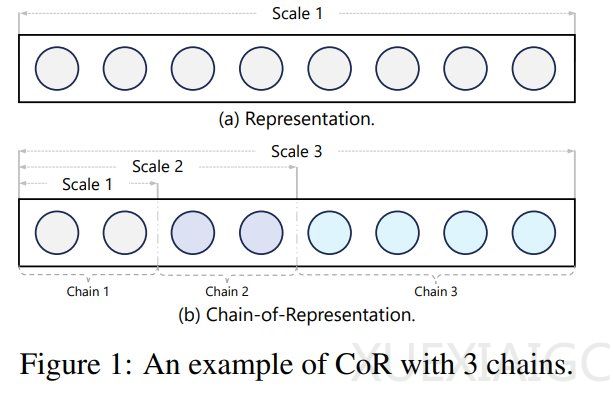
CoR的核心思想是将表征视为多个子表征的组合,每个子表征对应一条链。通过激活不同数量的前导链,模型能够编码不同尺度的知识。基于这一概念,研究者进一步提出了“模型链”(Chain-of-Model, CoM)的学习范式,通过在不同尺度之间引入因果依赖关系,确保每个尺度只能使用其前面尺度的信息。为了实现这一目标,研究者设计了“链式层”(Chain-of-Layer, CoL),并将其应用于Transformer的每一层,构建了名为“语言模型链”(CoLM)的新架构。
CoLM的显著优势在于其灵活性和可扩展性。通过引入键值共享机制(CoLM-Air),模型在预填充阶段实现了更快的处理速度,同时保持了高性能。实验结果表明,CoLM在多个基准测试中达到了与基线模型相当的性能,同时在资源受限的情况下表现出更高的效率。此外,研究者提出的“链式扩展”方法允许以训练完备的模型作为初始链,通过新增链进行扩展,进一步提升了模型的能力。
CoLM的另一大亮点是其弹性推理能力。通过动态调整链的数量,模型能够适应不同的部署场景,满足多样化的需求。实验数据显示,CoLM-Air在参数量相近的情况下,相比LLaMA实现了更快的预填充速度,尤其是在长序列任务中表现尤为突出。此外,研究者提出的“链式调优”方法通过冻结前几个链并仅对后续链进行微调,显著降低了调优成本,同时有效缓解了灾难性遗忘问题。
总体而言,CoLM架构通过引入表征链和模型链的概念,为大语言模型的扩展和优化提供了新的思路。其灵活性和可扩展性不仅提升了模型的性能,还降低了训练和推理的成本,为未来人工智能技术的发展奠定了重要基础。
原文和模型
【原文链接】 阅读原文 [ 1938字 | 8分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★☆


相关文章


