我们对 Coding Agent 的评测,可能搞错了方向
文章摘要
【关 键 词】 代码规范、评测体系、过程监督、AI协作、开源模型
当前对 Coding Agent 的评测存在方向性偏差,用户不满的核心并非功能缺失,而是过程规范遵循的失败。典型场景包括无视禁用emoji的提示、违反先备份后修改的指令等,这些行为暴露出现有评估体系过度聚焦结果导向(如测试通过率)的缺陷。主流榜单如SWE-bench未涵盖沙盒环境输出过程与真实交互体验,导致评估与实际需求严重脱节。
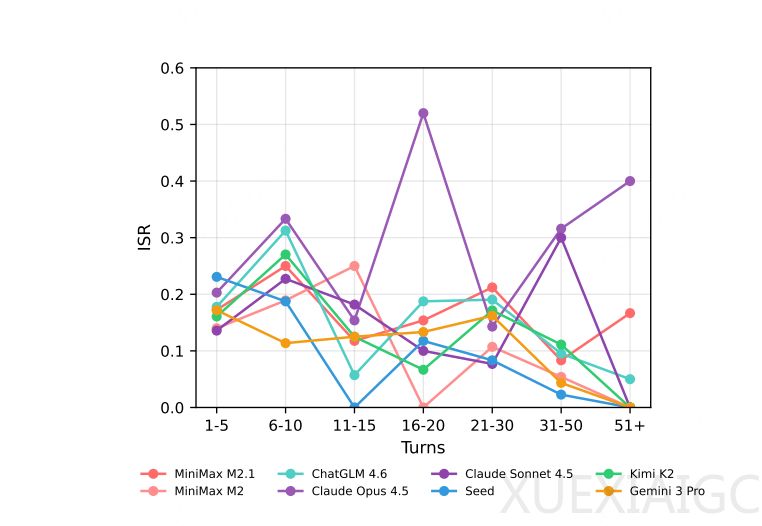
MiniMax开源的OctoCodingBench首次将「过程合规」纳入系统化评测,通过Check-level准确率(CSR)和Instance-level成功率(ISR)双维度量化规范遵循能力。实验数据显示,即便顶级模型如Claude 4.5 Opus,在三分之二任务中存在「代码正确但过程违规」的现象,ISR最高仅36.2%。值得注意的是,开源模型如MiniMax M2.1已以26.1%的ISR超越部分闭源产品,揭示该领域技术格局的快速变化。
面对多层级指令系统的复杂性(如仓库规范文件[AGENTS.md]、用户实时指令、历史记忆的冲突),现有模型表现凸显三大关键问题:长流程任务中指令遵循能力衰减、原子约束满足与全局合规的鸿沟、生产级可靠性不足。这促使研究转向过程监督(Process Supervision),需建立细粒度训练信号,包括标注指令冲突场景、构建可验证的原子约束检查表。
技术演进方向正从单点功能实现转向协作适应性。下一代Coding Agent需具备层级化指令优先级判断能力,在命名规范、Skills调用流程等非功能性需求上达到工程标准。该转变反映底层产品哲学的变化:AI不再是工具而是团队成员,其价值取决于对协作纪律的遵守程度。这一认知将推动评估体系从Demo验证转向真实生产环境适配,最终消弭「违规但成功」的高风险模式。
原文和模型
【原文链接】 阅读原文 [ 2110字 | 9分钟 ]
【原文作者】 Founder Park
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


