文章摘要
【关 键 词】 开源模型、注意力机制、数据处理、模型推理、商业部署
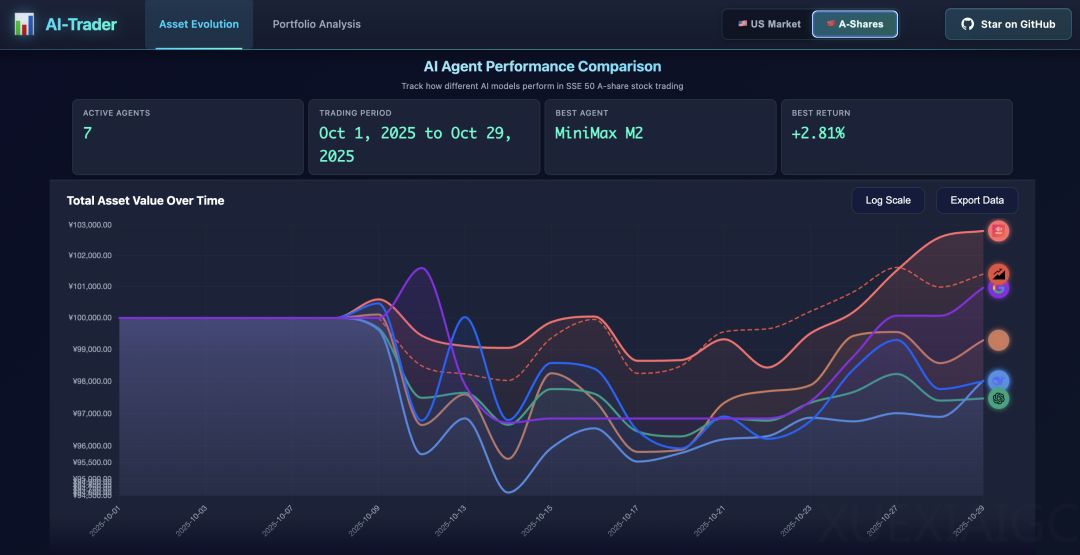
MiniMax M2开源大模型凭借其独特的技术路径和出色的实际表现成为社区焦点。该模型在香港大学AI-Trader模拟A股大赛中以10万本金20天盈利近3000元的成绩夺冠,其成功源于多项创新设计。最引人关注的是团队放弃省算力的Linear Attention,回归Full Attention机制。测试表明,Efficient Attention在长上下文场景会出现性能骤降,而Full Attention在复杂任务中展现出稳定优势,这揭示了当前评测体系的局限性——常规榜单难以区分Attention机制的真实差异。
技术实现上,M2团队构建了系统化的数据处理流程。通过实习生可复现的标准化操作,确保了数据质量的稳定性。数据筛选聚焦思维链完整性和响应多样性,刻意规避对特定榜单格式的过拟合。团队还建立了基于规则和模型判定的清洗机制,从源头减少幻觉等问题。数据覆盖范围的扩展与质量控制的结合,为模型泛化能力奠定了基础。
针对模型”高分低能”现象,团队提出“交错式思维链”(Interleaved Thinking)的创新方案。该方法将推理过程动态嵌入工具调用的每个关键节点,形成”计划-行动-反思”的闭环,显著提升了长链任务的容错率。在工具调用训练中,团队模拟了提示语变化、环境异常等真实场景扰动,使模型具备应对不确定性的能力。
MiniMax的技术选择始终以商业部署为导向,如早期对MoE架构的探索。M2的设计理念强调工程实用性而非理论最优,其技术博客详细披露了各项决策依据,为社区提供了可复现的工程范式。这种面向现实场景的系统性思考,展现了开源模型从实验室走向实际应用的关键路径。随着上下文长度增长带来的算力挑战,团队也指出未来可能需要重新评估Efficient Attention的潜力,但现阶段稳定性仍是首要考量。
原文和模型
【原文链接】 阅读原文 [ 2697字 | 11分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


