扩散语言模型新发现:其计算潜力正在被浪费?
文章摘要
【关 键 词】 机器学习、语言模型、并行解码、推理优化、模型训练
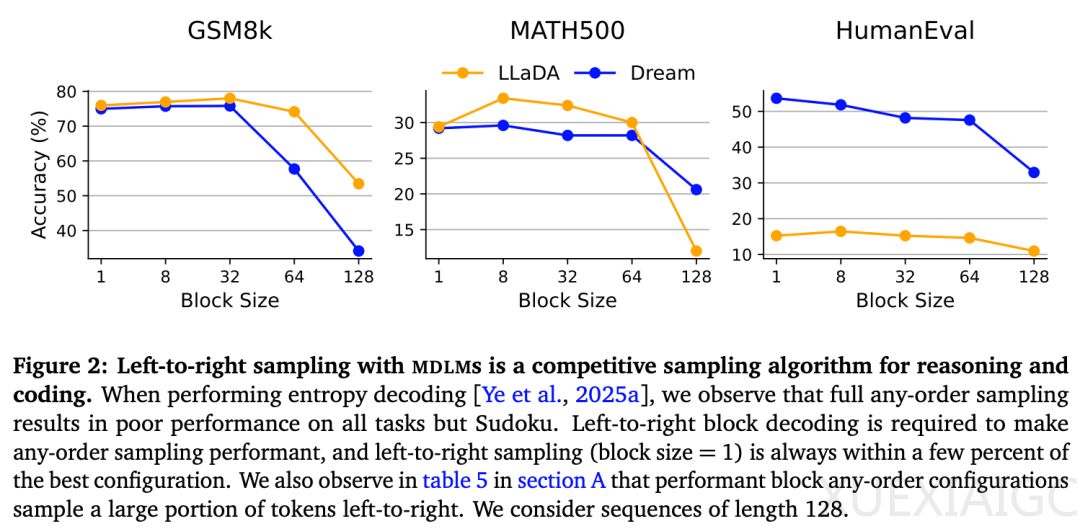
掩码扩散语言模型(MDLM)作为一种新兴的生成范式,挑战了传统自回归模型从左到右的token生成方式。这种模型通过训练时随机遮蔽序列位置并学习填充,具备多token并行解码和任意顺序生成的能力。然而最新研究发现,在数学和编码任务中,并行解码可能导致性能显著下降——即使仅并行生成两个token,模型在主流基准上的准确率也会降低。这一现象引发了对MDLM额外计算资源投入价值的质疑。
研究者通过系统实验揭示了MDLM的核心优势在于其独特的填充能力。通过”提示即填充”的新范式,模型可以在序列任意位置插入用户指定的上下文,突破了传统模型只能在序列起始处添加提示的限制。更突破性的是提出的”推理即填充”框架:预先构造包含明确推理位置和答案位置的模板,使模型能基于条件分布量化答案不确定性,实现提前退出机制。在GSM8k数据集上,该方法减少24%的函数调用且保持准确率不变。
针对多token解码的性能损失问题,研究团队提出自适应解决方案——多token熵解码(MED)。该方法通过监测被掩码位置的熵值,仅在条件熵低于阈值时启动并行解码,有效控制分布偏差。实验显示MED能在保持准确率的同时实现2-3倍推理加速,例如在HUMANEVAL任务上获得2.2倍速度提升。熵值监测机制与自回归顺序结合的AR-MED变体,进一步优化了解码稳定性。
MDLM的后验采样能力为模型微调开辟了新路径。通过从以答案为条件的后验分布中采样推理轨迹,研究者生成高质量的事后推理数据用于微调,使模型性能提升14.9%。更值得注意的是,模型中间步骤的答案对数概率与最终正确性呈现强相关性,这种内置的评估机制优于外部奖励模型,为自动化过滤低质量推理链提供了可靠指标。
在应用层面,该研究展示了MDLM三大革新性能力:通过答案熵监测实现的动态早停机制、基于条件分布的后训练数据自动生成、以及无需外部模型的密集反馈信号获取。这些特性使得MDLM在保持生成质量的前提下,显著降低了推理计算成本。特别在数独等逻辑任务中,MDLM展现出超越传统模型的优势,但其在数学推理场景的局限性也提示需要更精细的条件分布建模。这项研究为重新思考语言模型的训练目标与推理机制提供了实证基础,揭示了计算资源重新配置的可能性方向。
原文和模型
【原文链接】 阅读原文 [ 3889字 | 16分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


