文章摘要
【关 键 词】 AI模型、多模态推理、企业应用、训练策略、性能优化
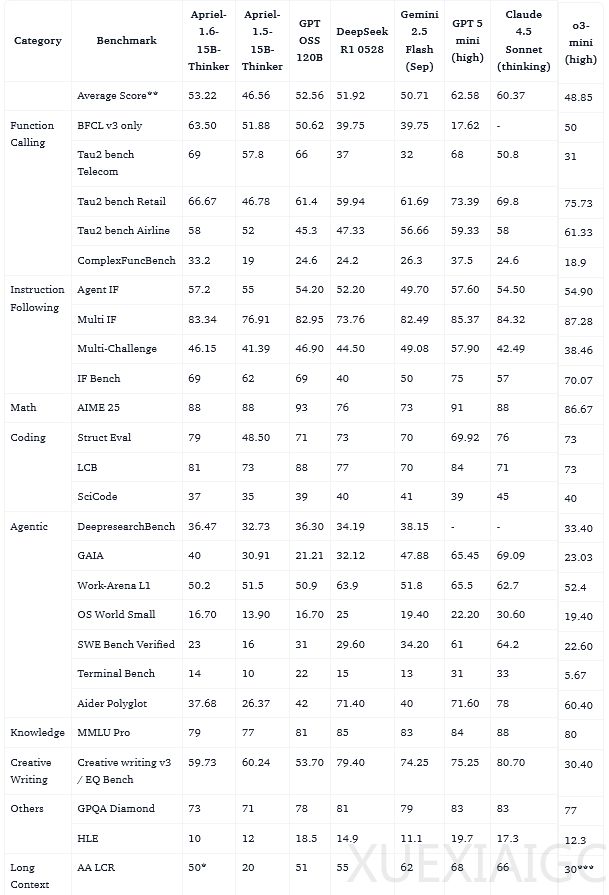
ServiceNow人工智能团队最新发布的Apriel-1.6-15b-Thinker模型,以150亿参数的轻量级体量,在多模态推理能力上实现了显著突破。该模型不仅击败了体量大其十倍的对手,还将推理Token的消耗量降低了30%以上,精准卡位企业级应用的高效甜蜜点。在Artificial Analysis Index中,Apriel-1.6获得了57分的高分,超越了Gemini 2.5 Flash、Claude Haiku 4.5等知名模型,并达到与Qwen3 235B A22B相当的水准,同时保持了极高的能效比。
训练过程体现了数据筛选与策略调优的精密工程。模型沿用了深度上采样阶段配合两个持续预训练阶段的整体流程。在深度上采样阶段,团队构建了高度多元化的语料库,包含35%的高质量网页内容、科学技术文献等,15%的NVIDIA Nemotron合成数据集,以及50%的预训练风格数据回放。第一阶段持续预训练扩展了数据混合配方,加入了全合成的文本样本与图文对,覆盖通用推理、知识问答、代码编写及创意写作等领域。多模态数据则涵盖文档与图表理解、OCR、视觉推理任务等,确保模型能处理复杂任务。纯文本持续预训练将序列长度扩展至49K,第二阶段则专注于视觉推理能力的打磨。这套训练流程在NVIDIA GB200s上仅消耗约10,000个GPU时。
监督微调阶段采用了包含240万个高信号文本样本的精选数据集,每个样本都包含显式的、分步骤的推理轨迹。数据质量被置于最高优先级,经过多级去重、内容过滤、LLM-as-Judge验证等严格处理。微调分为两个阶段:第一阶段是对240万个样本进行4个周期的纯文本大规模训练,简化了聊天模板并引入四个特殊Token以提升输出解析便捷性;第二阶段是轻量级的多模态运行,训练3个周期,利用从前代模型中拒绝采样的数据,确保模型保持强大的图像处理能力。
强化学习环节采用多阶段设置,覆盖视觉推理、通用视觉问答、OCR等图像领域,以及简单问答、数学数值推理、STEM多选题等跨域数据。奖励机制设计巧妙,模型因回答正确获得奖励,同时因冗长、格式错误等不良行为受到惩罚,鼓励在面对简单问题时直截了当,减少不必要的中间步骤。训练采用GSPO损失函数和VeRL框架,成功在提升推理深度的同时,将推理Token使用量减少30%以上。
性能测试显示,Apriel-1.6在工具使用、数学、编程、指令遵循及长上下文等多个领域表现卓越。在文本评估中,它超越了同等体量的对手,部分指标甚至优于参数量更大的模型。图像评估方面,通过VLMEvalkit工具测试,在数学推理、视觉问答、逻辑推理及图表分析等关键领域,Apriel-1.6在13个基准的Image Index平均分上比前代提高了4分。模型在智力与参数量的对比图表中位于最吸引人的象限,以150亿参数提供了媲美巨型模型的智力分数。
团队也指出了模型的局限性:面对复杂或低质量图像时OCR准确率可能下降;在人群或相似物体密集场景中细节捕捉和计数能力面临挑战;对高度详细或格式异常图表的解释可能不够完美;细粒度视觉定位的边界框预测有时不够精确。尽管如此,Apriel-1.6通过有效的数据策略和训练方法,证明了小规模计算也能诞生SOTA级别的模型,用更少的资源做更聪明的事,展现了AI进化的方向。
原文和模型
【原文链接】 阅读原文 [ 1727字 | 7分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


