文章摘要
Mistral AI发布了其首款推理模型Magistral,该模型旨在提升多语言推理能力和可解释性。Magistral分为两个版本:Magistral Small,一个24B参数的开源权重版本,可在Apache 2.0许可下自行部署;Magistral Medium,一个更强大的、面向企业的版本,在Amazon SageMaker上提供。Magistral的一个显著特点是支持多语言推理,尤其是解决了主流模型用欧洲语言的推理效果不如本土语言的缺陷。该模型通过微调多步逻辑,提升了可解释性,并在用户的语言中提供了可追溯的思考过程,能够实现大规模实时推理。
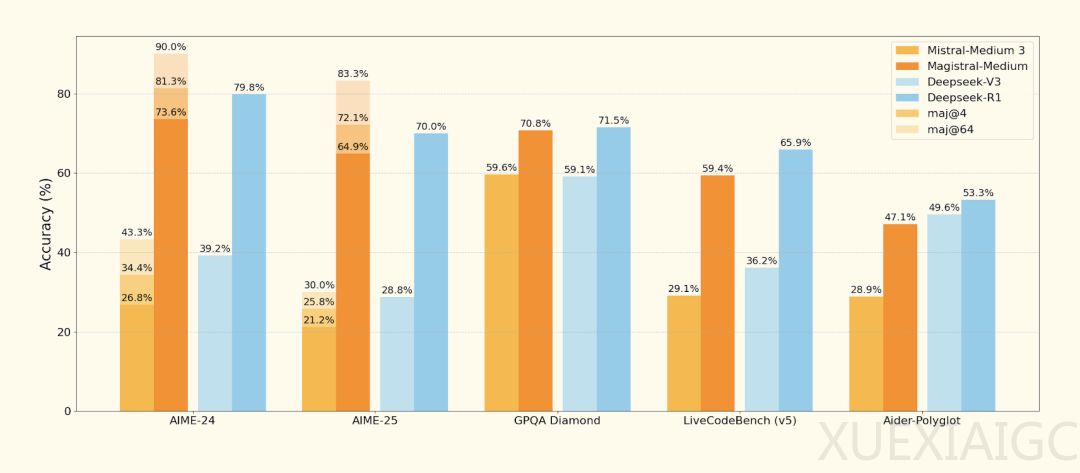
在技术层面,Magistral采用改进的Group Relative Policy Optimization(GRPO)算法,直接通过强化学习(RL)训练,不依赖任何现有推理模型的蒸馏数据。通过消除KL散度惩罚、动态调整探索阈值和基于组归一化的优势计算,Magistral在AIME-24数学基准上实现了从26.8%到73.6%的准确率跃升。此外,Magistral首创异步分布式训练架构,通过Generators持续生成、Trainers异步更新的设计,配合动态批处理优化,实现高效的大规模RL训练。
尽管Magistral在技术上取得了显著进展,但其发布并未与最新版的Qwen和DeepSeek R1进行直接对比,这引发了部分网友的质疑。在官方展示的基准测试结果中,DeepSeek-R1的数据并非最新,且比较行列里完全不见Qwen的身影。然而,与Mistral AI的初期模型Mistral Medium 3相比,Magistral在AIME-24上的准确率提升了50%。
此外,Magistral在Le Chat中的表现也值得关注,通过Flash Answers,Magistral Medium的token吞吐量比大多数竞争对手快10倍,这为实现大规模的实时推理和用户反馈提供了可能。这些创新使Magistral在无需预训练蒸馏的情况下,以纯RL方式为LLM的强化学习训练提供了新范式。
最后,尽管Mistral AI在技术上取得了显著进展,但其开源策略引发了部分争议。Stability AI前CEO建议Mistral AI应争取真正的开源来占据开源的领导地位。这一建议反映了业界对Mistral AI开源策略的期待与质疑。
原文和模型
【原文链接】 阅读原文 [ 844字 | 4分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek-v3
【摘要评分】 ★★☆☆☆


相关文章


