新架构模型HRM-Text创新纪录!1B参数、1000美元,图灵奖得主都亲自下场了
文章摘要
【关 键 词】 语言模型、架构创新、高效训练、递归计算、推理能力
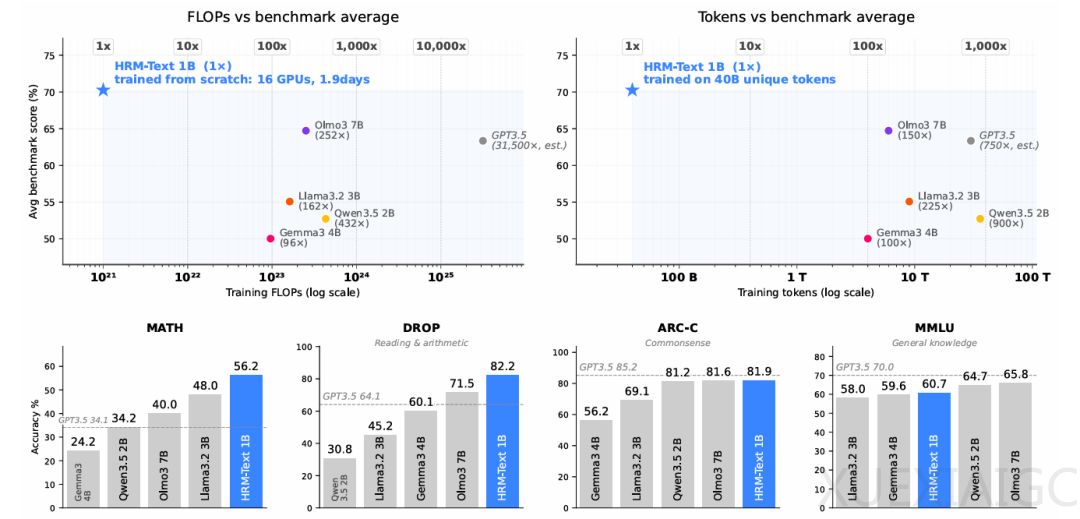
Sapient Intelligence发布的约1B参数语言模型HRM-Text在MATH、GSM8K和ARC-Challenge等推理基准测试中取得了优异成绩。其训练成本仅约1500美元,且从零预训练的数据使用量远低于主流同级模型。该模型证明了在有限数据和算力条件下,通过架构与训练目标的协同设计,能够显著提升基础模型的预训练效率。
在核心技术层面,HRM-Text实现了计算架构与训练目标的双重创新。在架构方面,模型引入了高低层双时间尺度模块,使有限参数在输出前进行多轮内部递归计算,从而有效增加了计算深度。为克服深层递归易导致的梯度消失或爆炸问题,研究引入了MagicNorm归一化与渐进式深层信用分配机制,确保了开放域语言任务中的训练稳定性。在训练目标方面,模型摒弃了全局自回归预测,采用仅对回答部分计算损失的策略,并结合PrefixLM注意力掩码,将训练信号高度集中于指令理解与答案生成过程。
就模型定位而言,HRM-Text目前是一个偏重任务执行与逻辑推理的紧凑型概念验证模型,在依赖广泛事实知识覆盖的基准测试中表现相对一般。针对这一局限,研究团队提出未来将推理核心与知识存储进行解耦,使紧凑模型专注于计算规划,而事实覆盖交由外部检索系统或可学习记忆模块处理。此外,该架构已从符号推理成功扩展至开放语言环境,并吸引了后续关于概率化多轨迹推理的学术研究。
总体而言,HRM-Text的探索展示了超越传统参数与数据规模扩张的新路径。重新设计底层计算结构能够有效改变模型性能、训练成本与能力之间的关系,为下一代智能系统在计算过程本身的优化提供了重要的理论基础与可复现的实践案例。
原文和模型
【原文链接】 阅读原文 [ 5456字 | 22分钟 ]
【原文作者】 机器之心
【摘要模型】 qwen3.7-max
【摘要评分】 ★★★★★


相关文章


