文章摘要
DeepSeek V4即将发布的消息引发行业高度关注,其前代产品DeepSeek-R1曾导致英伟达股价大跌17%,若V4实现技术突破,或对寻求巨额融资的美国AI公司及英伟达、谷歌等巨头产生显著影响。Anthropic发文称DeepSeek等三家中国AI公司对Claude进行“工业规模的蒸馏攻击”,被认为可能是舆论引导以减轻V4的潜在冲击。当前全球AI公司均聚焦智能体研发,DeepSeek联合北大、清华发布的最新论文正是瞄准这一趋势,提出的技术方案直指智能体大语言模型的核心性能瓶颈。
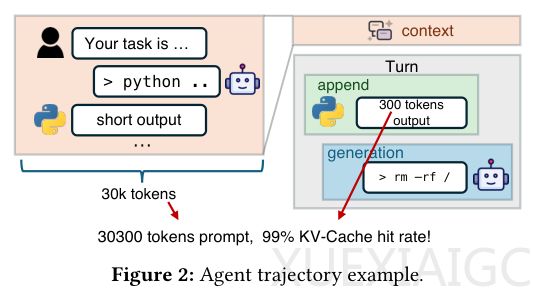
随着大型语言模型向自主解决多轮复杂任务的智能体演进,频繁多轮交互产生的极长上下文,使系统性能瓶颈从算力转移到键值缓存的存储读取上。传统预填充与解码分离架构中,预填充引擎独自承担所有缓存读取压力,导致网络拥堵和GPU空闲。硬件层面,近年网络带宽和显存容量增长落后于GPU算力的飞跃,进一步加剧了内存和通信瓶颈,让高性能GPU因缓存加载速度受限而陷入闲置状态,张量核心等计算单元难以发挥极致性能。
为突破这一瓶颈,团队提出DualPath双通道加载技术,巧妙调用解码节点的闲置存储网络带宽,让智能体大语言模型推理吞吐量直接飙升近两倍。该技术在传统存储到预填充节点路径外,开辟了存储到解码节点的新路径,结合全局调度算法彻底打通预填充与解码节点间的传输壁垒,在不增加硬件成本的前提下实现性能飞跃。同时,系统采用虚拟通道技术隔离模型推理与缓存传输的流量,为高优先级的推理通信保留99%带宽;智能调度器根据节点存储队列长度、GPU负荷、显存容量等动态分配任务,避免局部资源过载,确保算力与网络资源高效利用。
大量测试验证了技术的有效性,在离线批量推理场景中,双通道架构实现了高达1.87倍的吞吐量跃升;在线服务场景下,支持的最高并发请求率翻了将近一倍,词间生成延迟未受额外缓存搬运影响。消融实验显示,双通道加载使任务完成时间下降38%,结合调度算法最终实现45%的速度优势。在千张GPU规模的集群测试中,系统展现出完美的线性扩展能力,为未来复杂智能体大模型应用扫清了底层基础设施障碍。
原文和模型
【原文链接】 阅读原文 [ 4229字 | 17分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 doubao-seed-1-8-251228
【摘要评分】 ★★★★☆


相关文章


