更大,还能更快,更准!蚂蚁开源万亿参数语言模型Ling-1T,刷新多项SOTA
文章摘要
【关 键 词】 大模型、开源技术、人工智能、参数规模、推理效率
蚂蚁集团推出的Ling-1T大模型标志着开源大模型领域的重要突破。作为百灵大模型Ling 2.0系列的首款旗舰产品,该模型采用高效的MoE架构,总参数规模达到万亿级别,成为当前开源推理模型的参数天花板。值得注意的是,Ling-1T在保持万亿级参数储备的同时,通过”大参数储备+小参数激活”的范式,实现了百亿级计算开销的产业级落地,有效平衡了规模、速度与推理精度之间的矛盾。
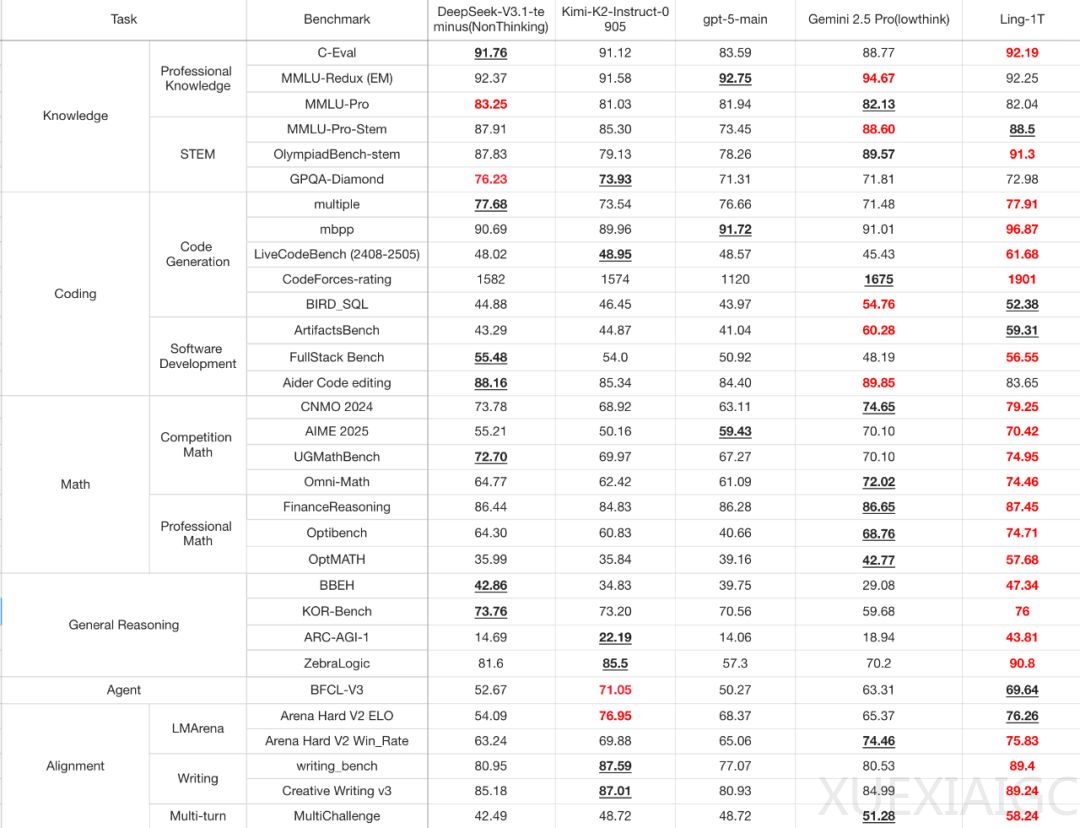
在技术性能方面,Ling-1T在多维基准测试中展现出卓越表现。特别是在编程与数学推理等高密度任务上,该模型稳居第一梯队:在LiveCodeBench真实编程任务中得分最高,在ArtifactsBench复杂软件建模中仅次于Gemini-2.5-Pro。数学推理方面,Omni-Math与UGMathBench双双突破74分,金融推理更达到87.45的高分。知识理解维度同样出色,在C-Eval、MMLU等关键数据集上普遍领先同类模型1-3个百分点。
模型的高效性体现在其独特的架构设计上。虽然每个MoE层拥有256位专家,但每次推理仅激活约50B参数,通过精选8位专家参与思考的方式实现”按需思考”。配合分组查询注意力机制,该模型支持128K长上下文处理,在保持深度理解能力的同时避免推理速度下降。实际测试显示,在AIME-25数学推理测试中,Ling-1T以70.42%的准确率与Gemini-2.5-Pro持平,但消耗的token数量更少。
训练方法的创新是模型性能的另一关键。蚂蚁构建了包含20T+高推理密度语料的数据体系,采用三阶段训练策略:先以10T高知识密度语料建立通识基础,再用10T高推理密度语料强化逻辑,最后通过演进式思维链预热推理能力。训练过程中应用Ling Scaling Laws自动优化参数配置,配合WSM调度器提升收敛效率。后训练阶段采用创新的LPO优化方法,以句子为单位对齐人类语义,确保生成内容的逻辑连贯性。
在实际应用层面,Ling-1T展现出广泛适用性。测试显示,该模型能精准完成前端界面设计、科技文案创作、数学问题解答等多样化任务。在创意写作中,它能基于《星际穿越》灵感创作播客开场白;在工具调用场景下,可准确推荐武汉周边小众徒步路线并给出专业建议。这些表现验证了模型在编程、科普、创意辅助等领域的实用价值。
蚂蚁集团选择全面开源Ling-1T及其技术栈,包括ATorch框架和强化学习工具链,推动AI技术普惠化。这种开放策略既有利于社区共同提升模型质量,也降低了企业应用门槛,使万亿级大模型能力能够根据不同场景需求灵活部署——从手机端的Ling-mini到云端的Ling-1T完整版。这种分层设计理念,配合MoE架构的高效特性,为AI技术的大规模产业落地提供了可行性方案。
原文和模型
【原文链接】 阅读原文 [ 4356字 | 18分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


