最新外国「自研」大模型,都是套壳国产?
文章摘要
【关 键 词】 AI模型、开源社区、中文输出、代码工具、全球竞争
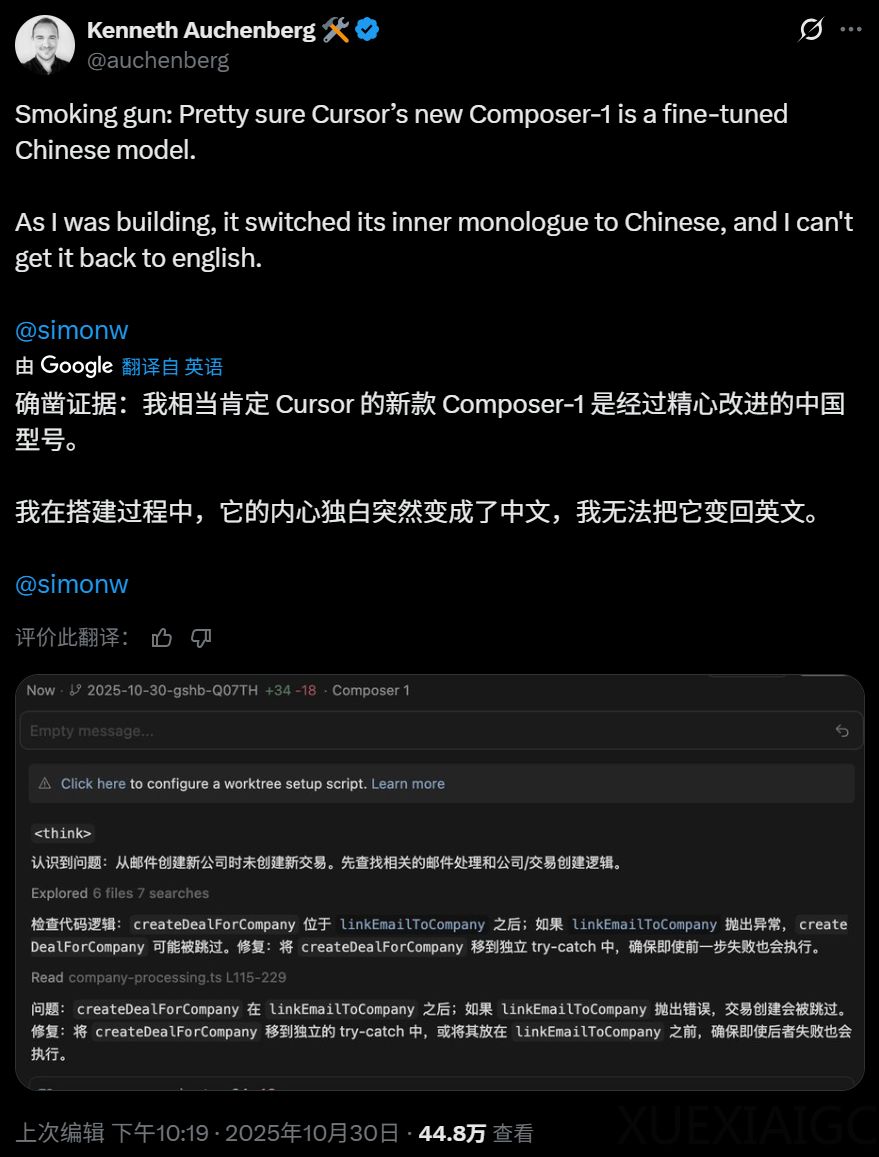
Cursor发布的2.0版本更新中,其自主研发的代码模型Composer表现出与国产模型相似的行为特征,在推理过程中频繁输出中文内容,引发开发者对其技术来源的猜测。该MoE架构模型通过强化学习训练,在内部基准测试中展现出行业领先的编码能力,生成速度达到同类产品的四倍。其研发过程中采用的Cheetah原型系统为交互式编码体验提供了技术支撑,但语言输出特征使业界怀疑其可能基于Qwen Code等中国模型开发。
同期,Cognition公司推出的SWE-1.5模型同样引发技术溯源讨论。用户通过越狱测试发现该模型自报基于智谱AI的GLM架构,Cerebras硬件平台随后发布的zai-glm-4.6编码模型进一步佐证了这一技术路线。系统架构师Daniel Jeffries分析指出,当前主流趋势是企业在开源基座模型上进行微调,而非从零训练,这种模式既降低研发成本又提升效率。他强调开源生态对创新的关键作用,批评部分公司对专有模型的过度保护已阻碍行业发展。
行业数据显示中国开源模型正取得显著优势。黄仁勋在GTC大会上展示的数据表明,通义千问系列占据全球开源模型下载量的主要份额,其衍生模型数量持续领先。HuggingFace趋势榜和ArtificialAnalysis基准平台的前列位置多被MiniMax、DeepSeek等中国模型占据,反映出技术能力和市场接受度的双重优势。这种现象标志着全球AI竞争进入多极化阶段,中国开源模型不仅支撑本土创新,更成为国际企业开发的重要基础。
模型性能的快速迭代正在重塑行业格局。国产模型在推理速度、多模态处理等关键技术指标上建立壁垒,其开源策略加速了技术扩散。从Cursor到Cognition的案例显示,初创公司通过整合优质基座模型可实现快速产品化,这种模式可能催生更多”站在巨人肩膀上”的创新。当前技术演进路径表明,开源协作与垂直领域微调的结合正成为AI商业化的重要范式,而中国模型在该领域已形成系统性优势。
原文和模型
【原文链接】 阅读原文 [ 1509字 | 7分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★☆☆☆


相关文章


