文章摘要
【关 键 词】 视频理解、AIGC、数据重组、计算成本、模型训练
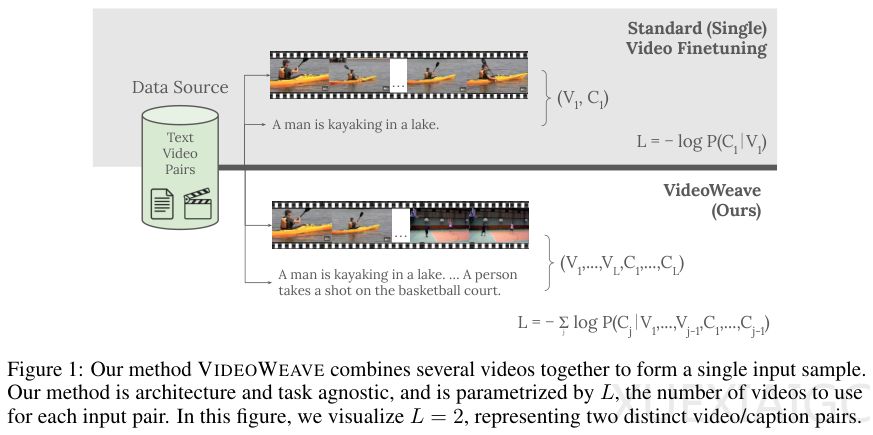
斯坦福大学、微软研究院和威斯康辛大学团队提出了一种名为VideoWeave的数据中心化方法,通过重组短视频素材显著提升了AI对长视频的理解能力,且无需增加计算成本。传统视频语言模型训练面临高昂的计算开销和高质量数据匮乏的挑战,尤其是长上下文理解能力的不足。现有数据集多为短片段配简单描述,而实际应用需要模型理解半小时甚至更长的复杂内容。
VideoWeave的核心创新在于通过拼接多个无关短视频构建合成长上下文训练数据。这种方法不改变模型架构,而是调整输入数据的组织形式。例如,在16帧的计算预算下,传统方法从单一视频采样,而VideoWeave可能从4个视频各取4帧或16个视频各取1帧,按序拼接成新序列。这种策略迫使模型适应画面内容的剧烈变化,从而增强其理解能力。模型必须关注每一帧的独特特征,而非依赖相邻帧的相似性。
研究团队对比了随机拼接与基于视觉或文本聚类的拼接效果。出乎意料的是,随机拼接的表现优于精心设计的聚类方法。视觉聚类导致模型因内容相似而“偷懒”,文本润色则因丢失细节或引入幻觉而降低准确性。实验数据显示,在总帧数固定时,两个视频各贡献8帧的拼接方式达到最佳平衡,既保证片段连贯性,又提供足够上下文切换。
VideoWeave证明了数据重组比模型架构调整更具性价比。定性分析显示,经该方法训练的模型能更准确捕捉关键信息,如“信风减弱”与厄尔尼诺现象的关系。在属性感知、空间感知和时序推理等维度上,模型表现均有显著提升。这种策略模拟了高效学习过程,通过穿插不同知识点锻炼模型的融会贯通能力。
该方法不仅为学术研究提供了新思路,对工业界的大规模视频预训练也具有重要参考价值,尤其是在不增加硬件投入的情况下挖掘模型潜力。通过改变数据使用方式,VideoWeave为长视频理解这一难题提供了简单而有效的解决方案。
原文和模型
【原文链接】 阅读原文 [ 1999字 | 8分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


