文章摘要
随着大模型技术的快速发展,多模态数据处理逐渐成为研究热点。多模态生成任务通过整合文本、图像、音频等多种类型的数据,实现不同模态之间的相互转换与生成。然而,现有模型在处理复杂任务时仍面临诸多挑战,尤其是如何有效对齐和融合不同模态数据,成为提升模型性能的关键难题。松下开发的OmniFlow模型,作为多模态大模型的代表,通过模块化设计和多模态引导机制,显著提升了多模态生成任务的效率和可控性。
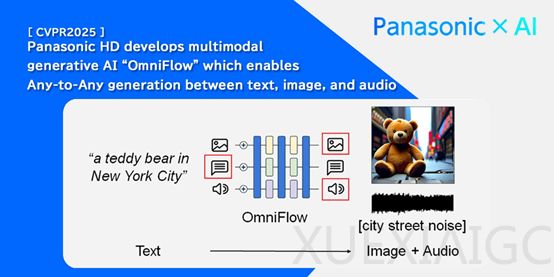
OmniFlow采用模块化设计理念,允许各个组件独立预训练,从而优化特定模态或任务的处理能力。例如,文本处理模块通过大规模文本数据集预训练,提升语言理解和生成能力;图像生成模块则通过大量图像数据训练,增强图像生成的质量和准确性。这种设计不仅提高了训练效率,还避免了传统模型整体训练时的资源浪费问题。完成预训练后,OmniFlow能够灵活合并各组件并进行微调,快速组合出适合特定任务的架构,显著提升了模型的扩展性和适应性。
多模态引导机制是OmniFlow的另一大技术亮点,它增强了生成过程的可控性。传统多模态生成模型往往缺乏有效引导,导致生成结果与用户期望存在偏差。OmniFlow通过引入引导机制,允许用户精确控制输入和输出模态之间的交互。例如,在文本到图像的生成任务中,用户可以通过设定引导参数,强调图像中的特定元素或调整整体风格,从而控制生成图像的具体内容和特征。
在数据处理流程中,OmniFlow首先将多模态输入转换为潜在表示。文本输入通过自然语言处理技术转化为向量形式,提取语义信息;图像输入利用卷积神经网络提取特征;音频输入则通过音频处理算法转换为适合模型处理的潜在表示。随后,这些潜在表示通过时间嵌入编码和Omni-Transformer块进一步处理。时间嵌入编码捕捉数据中的时间序列信息,尤其适用于音频等具有时间特性的数据;Omni-Transformer块则基于Transformer架构改进,通过多头注意力机制等技术,实现不同模态数据之间的交互与融合。
实验结果表明,OmniFlow在多模态生成任务中表现出色。在文本到图像生成任务中,OmniFlow在MSCOCO-30K和GenEval基准测试中均取得了显著成果。通过FID指标评估,其生成的图像与输入文本的匹配度极高,CLIP分数也反映了图像与文本之间的语义一致性。在文本到音频生成任务中,OmniFlow生成的音频在语音相似度和质量评分方面表现优异,音频清晰流畅,无明显噪音或失真现象。这些实验结果充分验证了OmniFlow在多模态生成任务中的卓越性能。
原文和模型
【原文链接】 阅读原文 [ 1394字 | 6分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-v3
【摘要评分】 ★★★☆☆


相关文章


