文章摘要
【关 键 词】 大模型、即时更新、知识内化、技能适配、跨模态
当前大型语言模型在长效记忆和持续适配方面存在核心发展瓶颈,缺乏长效记忆会引发交互摩擦与信息断层,增加系统响应时间,缺乏持续适配能力则会让模型无法从过往交互中积累经验,导致用户交互过程始终繁琐。业界传统解决方案存在明显效率瓶颈,将新文档塞入上下文窗口的做法,会带来持续的高延迟与显存开销,键值缓存预填充等手段无法从根本解决问题,一旦文档长度超出上下文窗口限制就会失效;上下文蒸馏虽能将新信息编码进模型参数,但知识更新过程缓慢、计算成本高昂。针对模型技能适配的传统微调方案,需要反复完成数据收集、筛选与训练流程,极大拖慢新功能开发速度。微调和上下文蒸馏的共同瓶颈在于,部署阶段更新模型的信息传输路径缓慢且造价高昂。
Sakana AI提出基于成本分摊概念的全新策略,通过训练超网络生成即插即用的低秩自适应模块(LoRA),提前消化昂贵训练成本,实现低延迟的模型按需即时更新,可将文档瞬间转化为模型内在记忆,或将简单任务描述转化为专属专业技能。该工作流被拆分为两个独立阶段,元训练阶段投入较高算力一次性训练超网络,使其掌握根据不同输入生成高效自适应更新的能力,属于一劳永逸的前期算力投资;部署阶段仅需不到一秒的单次前向传播,即可生成定制化更新模块,彻底省去繁杂昂贵的逐个任务优化流程。
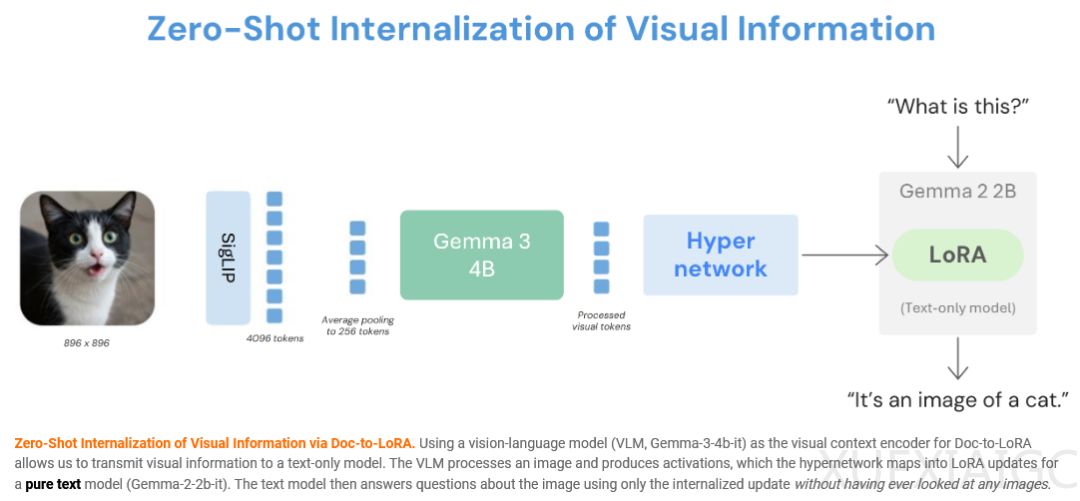
在知识内化场景中,该技术可将整篇文档提炼为自适应模块融入基础模型,打造持久模型记忆,原始文档无需再占用宝贵的上下文窗口,大幅削减系统延迟与显存消耗。该机制还可突破纯文本模态限制,实现跨模态信息迁移,实验结果显示,纯文本模型依托该技术,仅通过超网络映射视觉语言模型提取的图像特征,就在ImageNet十类子集测试中取得75.03%的准确率,实现了跨模态信息的无损传递。在技能适配场景中,超网络可仅依靠自然语言撰写的任务描述,瞬间生成可用的适配模块,让模型快速掌握新技能。该机制可利用用户交互间隙的闲置时间完成信息内化与模型更新,无需全量微调即可实现大规模模型个性化定制与不间断持续学习。未来该更新生成器有望成为基础模型的标准化底层接口,可融合多模态信息,持续输出模块化适配补丁,类似人脑在睡眠中完成记忆内化的过程。
原文和模型
【原文链接】 阅读原文 [ 2606字 | 11分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 doubao-seed-2-0-lite-260215
【摘要评分】 ★★★☆☆


相关文章


