文章摘要
【关 键 词】 AI技术、3D重建、视频处理、动态场景、深度学习
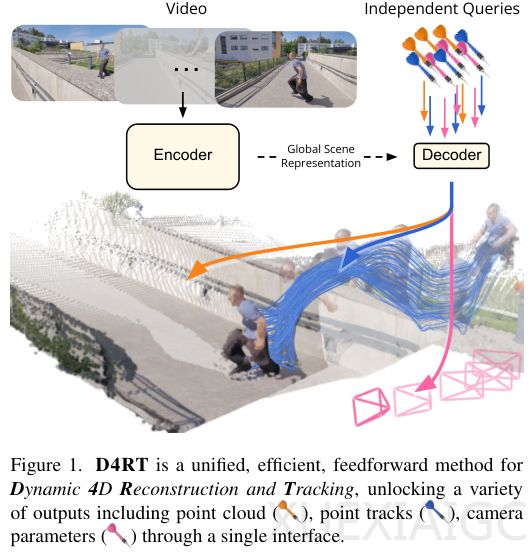
谷歌DeepMind联合伦敦大学和牛津大学发布的D4RT时空重建框架,彻底改变了传统视频3D重建的方式。D4RT不再采用一次性计算整个场景的笨重方法,而是通过按需查询的机制,实现了高效、精准的动态场景理解。这一创新使得计算机能够像人类一样自然地理解三维动态世界,解决了长期以来困扰AI的难题。
传统方法在处理视频3D重建时,通常需要逐帧计算每个像素的3D位置、深度和形状,计算量巨大且容易出错。D4RT的核心逻辑是“按需提问”,它先将视频的全局场景信息压缩成一个高效的表示,随后通过轻量级解码器回答用户的特定问题。这种设计不仅大幅降低了计算复杂度,还提高了处理速度,训练过程也更加高效。D4RT的统一接口设计使其能够同时处理多种3D任务,如点云重建、轨迹追踪和相机参数估计,避免了传统多模型拼接的复杂性。
D4RT的工作流程分为编码和解码两个阶段。编码阶段将视频信息压缩成全局场景表示,解码阶段则通过灵活的时空坐标系回答用户问题。这种设计实现了时间和空间的完全解绑,用户可以从任意视角和时间点查询场景信息。实验表明,D4RT的速度达到每秒200帧以上,比同类方法快9到100倍。其独特的“聪明收割机”算法进一步优化了计算效率,通过动态分配计算资源,避免了重复计算,速度提升了5到15倍。
在性能测试中,D4RT展现了卓越的准确性和鲁棒性。在TAPVid-3D测试中,D4RT无论是已知还是未知相机参数,均表现出色,尤其在复杂动态场景下的空间理解能力远超其他方法。在深度估计和点云重建任务中,D4RT在Sintel等高难度数据集上的误差极低,相机姿态估计的准确性也显著优于现有模型。研究人员发现,D4RT的解码器在回答问题时结合RGB Patch信息,大幅提升了追踪和重建的精度。
D4RT的成功不仅在于其技术创新,更在于其优雅的设计理念——将复杂的动态场景理解转化为高效的按需查询问题。这一框架为未来视频处理、3D重建和动态场景分析提供了新的方向,展现了AI在理解和重建真实世界方面的巨大潜力。
原文和模型
【原文链接】 阅读原文 [ 2408字 | 10分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


