没想到,最Open的开源新模型,来自小红书
文章摘要
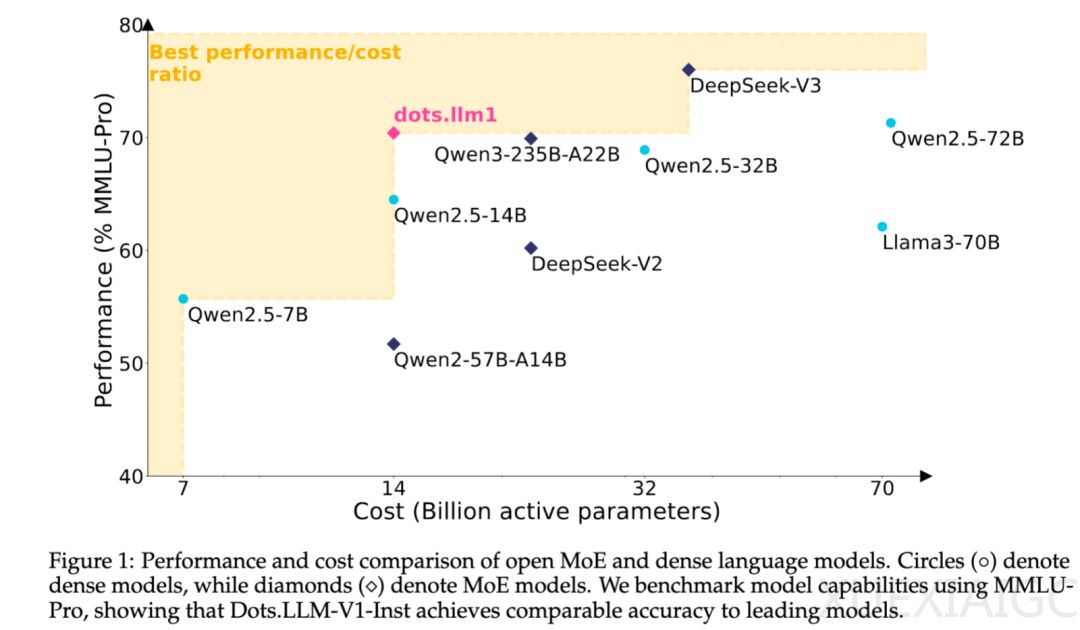
小红书近期开源了其首个自研大模型dots.llm1,该模型由小红书hi lab团队研发,参数总量为142B,激活参数为14B,属于中等规模的MoE(Mixture of Experts)模型。尽管参数规模不大,但dots.llm1在激活14B参数的情况下,在中英文通用场景、数学、代码生成和对齐任务上表现出色,与Qwen2.5-32B-Instruct和Qwen2.5-72B-Instruct等模型相比具备较强的竞争力。特别是在与Qwen3-32B的对比中,dots.llm1在中英文、数学和对齐任务上的表现接近甚至更强。
dots.llm1的开源力度堪称行业天花板,不仅开源了模型本身,还提供了预训练阶段的多个checkpoint、长文base模型以及详细的训练参数信息,如lr schedule和batch size等,极大地方便了开发者进行二次创作和继续预训练。这一举措标志着小红书在基础模型研发上的重要进展,也是其主动与技术社区展开对话的关键一步。
在模型的实际应用测试中,dots.llm1展现了强大的中文理解能力。例如,在面对复杂的“弱智吧”问题时,模型能够通过逐步拆解句子结构,准确找出“偷”这一动作的执行者,并给出正确答案。此外,模型在文本写作和编码任务中也表现出色,能够生成具有“活人味”的藏头诗,并创建响应式的城市天气卡片组件,展示了其多场景应用的能力。
dots.llm1的成功离不开其高效的数据处理和训练策略。模型使用了11.2T的高质量token数据进行预训练,数据主要来源于Common Crawl和自有Spider抓取的web数据。hi lab团队通过三道工序严格把控数据质量,确保数据的准确性和安全性。值得注意的是,dots.llm1并未使用合成语料,这表明即便不依赖大规模数据合成,也能训练出强大的文本模型。
在训练效率方面,hi lab团队与NVIDIA中国团队合作,提出了一套创新的解决方案:interleaved 1F1B with A2A overlap。该方案通过让EP A2A通信与计算重叠,显著提升了训练效率。实测结果显示,与NVIDIA Transformer Engine中的Grouped GEMM API相比,hi lab实现的算子在前向计算中平均提升了14.00%,在反向计算中平均提升了6.68%。
dots.llm1的模型设计借鉴了DeepSeek系列的经验,采用了WSD学习率调度方式,训练过程分为稳定训练和退火优化两个阶段。在稳定训练阶段,模型保持3e-4的学习率,使用10T token语料进行训练;在退火优化阶段,学习率逐步降低,数据方面强化了推理和知识类型语料。最终,模型通过两阶段的监督微调进一步提升了其理解力和执行力。
总的来说,dots.llm1的开源不仅展示了小红书hi lab团队的技术实力,也为开发者提供了一个值得信赖的模型基座。通过与社区的互动,hi lab团队有望进一步提升模型性能,为大模型领域注入更多可能性。
原文和模型
【原文链接】 阅读原文 [ 2747字 | 11分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章


