文章摘要
【关 键 词】 多模态幻觉、置信失准、CA-TTS框架、感知钝化、Test-Time Scaling
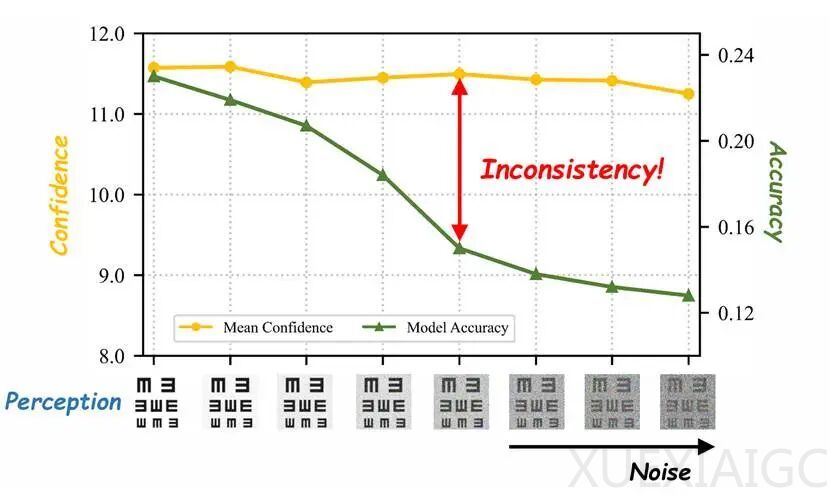
本文研究聚焦于多模态大模型在视觉推理中普遍存在“盲目自信”现象,即当输入图像严重退化时,模型准确率大幅下降,而置信度却几乎不变。该现象被定义为“感知钝化”,其核心问题是模型对视觉证据质量变化缺乏敏感性,导致在信息模糊时仍给出高置信答案,进而诱发系统性幻觉与误判。为解决此问题,研究团队提出CA-TTS(Confidence-Aware Test-Time Scaling)框架,包含两个关键阶段:训练阶段的CDRL(Confidence-Driven Reinforcement Learning)与推理阶段的置信度驱动资源调度机制。
CDRL模块通过强化学习,在同一问题的原始与加噪图像上并行训练模型,设计双重奖励函数——“感知敏感性奖励”引导模型在不同清晰度下产生显著置信度差异,“校准一致性奖励”则鼓励正确预测伴随高置信,错误预测则应伴随低置信。实验证明,该策略使模型在噪声扰动下的置信度下降幅度达训练前的4.3倍以上,且在遮挡、视角变换等条件下,置信度均显著下调,有效修正了原有“越模糊越自信”的反常行为,提升ECE与AUC指标,实现了“置信度真正与视觉证据对齐”。
在推理阶段,CA-TTS将校准后的置信度转化为动态调度信号,构建三个协同模块:Self-Consistency采用置信度加权投票取代传统多数投票;Self-Reflection由专家模型作为Critic介入,识别置信不足时生成批评意见引导模型重新推理;Self-Check在视觉层面对输出做自检,对比原图与加噪图响应分布变化以验证答案对视觉线索的依赖性。研究指出,该闭环设计超越常规Tree-of-Thoughts的简单多轮扩展,可在任一阶段出现偏差时被后续环节纠正。
实验表明,CA-TTS在四个主流视觉推理基准上全面达到SOTA,其中Math-Vision准确率从23.0%提升至42.4%,MMMU提升17.5个百分点;消融分析显示,CDRL贡献3.4%,CA-TTS独立提升15.0%,二者组合总提升19.4%,体现明显协同效应。更关键的是,其test-time scaling斜率高达3.65,远超传统方法,说明增加采样并非随机试探,而是高效聚焦不确定区域,能持续提升直至更高性能区间。这揭示出:置信度校准不仅是精度优化,更是重新定义算力分配效率上限的核心路径。
最终,研究倡导“先感知后推理”的范式变革,强调视觉理解可靠性必须优先于复杂推理逻辑。尽管当前应用仍面临成本与场景限制,但这一思路已为多模态系统在高风险领域实现“知之为知之”的可信赖推理奠定基础,标志着从“推理主导感知”到“感知引导推理”的理论跃迁。
原文和模型
【原文链接】 阅读原文 [ 2480字 | 10分钟 ]
【原文作者】 量子位
【摘要模型】 qwen3-vl-flash-2026-01-22
【摘要评分】 ★★★★★


相关文章


