文章摘要
【关 键 词】 OCR、开源模型、轻量化、视觉语言、强化学习
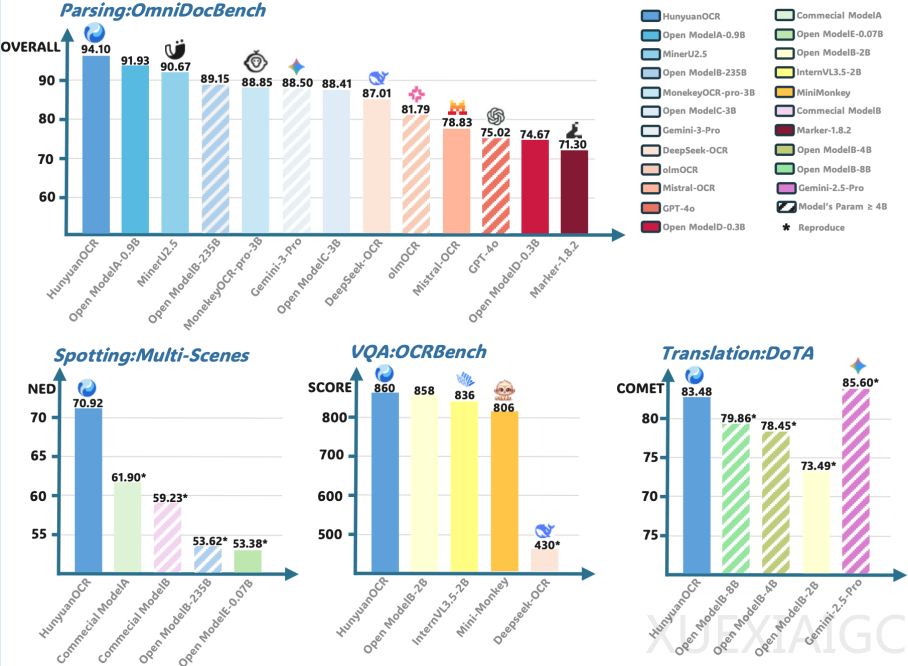
腾讯混元大模型团队推出的HunyuanOCR模型是一款商业级开源视觉语言模型,专为OCR任务设计,参数规模仅1B,兼具轻量与高性能特性。该模型在文本检测识别、复杂文档解析等感知任务上超越所有公开方案,并在ICDAR 2025 DIMT挑战赛小模型赛道夺冠,OCRBench上创下3B以下模型最优成绩。其技术架构融合原生ViT与轻量LLM,通过三大突破解决行业痛点:全能与高效统一、极简端到端架构、数据驱动与RL创新,目前已登陆Hugging Face趋势榜前四,GitHub标星超700。
模型核心技术围绕轻量化结构设计、高质量数据生产、应用导向预训练及OCR定制强化学习展开。采用SigLIP-v2-400M视觉编码器与Hunyuan-0.5B语言模型协同架构,引入XD-RoPE技术实现多维度信息解耦对齐,支持任意分辨率输入与跨页逻辑推理。与传统级联方案不同,其纯粹的端到端范式通过单次推理即可完成复杂任务,显著降低错误累积风险。预训练数据体系包含2亿多图像-文本对,覆盖9大核心场景和130种语言,通过SynthDog框架实现多语言段落渲染与Warping变形合成,结合自动化QA流水线提升跨语言泛化与复杂场景鲁棒性。
训练策略采用四阶段渐进式方案:前两阶段侧重视觉-语言对齐与通用理解能力,后两阶段扩展至32k上下文窗口并聚焦应用适配。强化学习方案创新性地将GRPO算法与格式约束结合,针对不同任务设计自适应奖励机制——检测识别任务采用IoU与编辑距离复合指标,翻译任务引入去偏归一化软奖励。这种混合策略使轻量模型在边缘设备部署中仍能保持高精度输出。
项目已全面开源模型参数与高性能vLLM部署方案,技术细节通过论文与开源平台公开。团队特别强调,该模型通过统一指令模板与标准化输出格式,显著提升了工业落地场景中的响应一致性与结构化处理能力,为OCR领域提供了新的轻量化技术范式。
原文和模型
【原文链接】 阅读原文 [ 2413字 | 10分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


