清华、NVIDIA、斯坦福提出DiffusionNFT:基于前向过程的扩散强化学习新范式,训练效率提升25倍
文章摘要
【关 键 词】 扩散模型、强化学习、前向优化、负例感知、生成对齐
清华大学朱军教授团队、NVIDIA Deep Imagination研究组与斯坦福Stefano Ermon团队联合提出了一种名为Diffusion Negative-aware FineTuning(DiffusionNFT)的全新扩散模型强化学习范式。该方法首次突破现有强化学习对扩散模型的基本假设,直接在前向加噪过程上进行优化,在彻底摆脱似然估计与特定采样器依赖的同时,显著提升了训练效率与生成质量。这一创新由清华大学计算机系博士生郑凯文和陈华玉作为共同一作完成。
现有方法在将强化学习应用于扩散模型时面临多重根本性局限。这些局限包括似然估计困难、前向-反向过程不一致、采样器受限以及对无分类器引导(CFG)的依赖与复杂性。DiffusionNFT通过将强化学习直接作用于扩散的前向加噪过程而非反向去噪轨迹,实现了范式性的转变。该方法的核心机制包括正负对比的改进方向、负例感知微调(NFT)以及强化指导。这种设计使DiffusionNFT同时满足前向一致性、采样器自由、似然无关和CFG-free原生优化等优势。
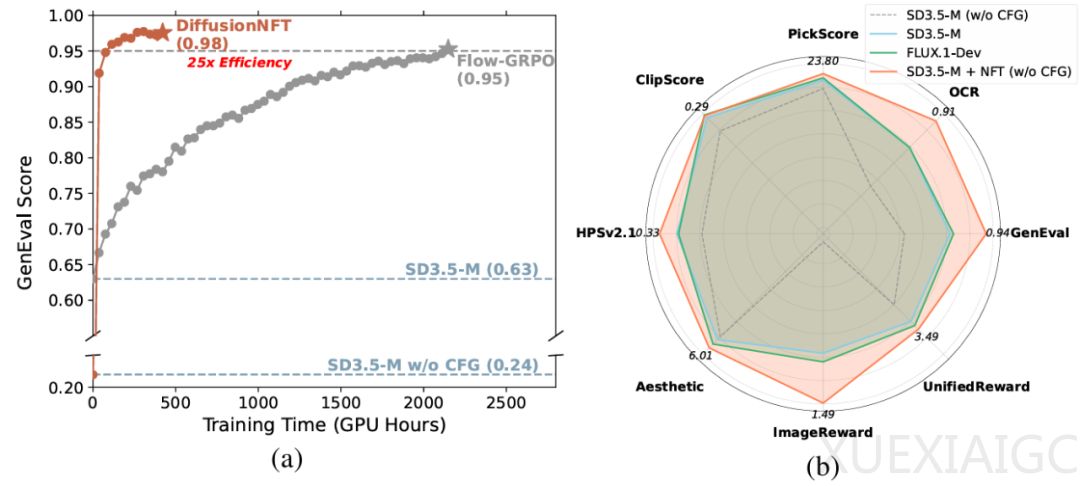
在实验验证方面,研究团队在多个奖励模型上测试了DiffusionNFT的有效性。结果显示,DiffusionNFT在GenEval任务上仅需1k步就能将得分从0.24提升至0.98,而现有方法FlowGRPO需要超过5k步才能达到0.95。该方法在不同任务上表现出3×~25×的训练效率优势。即便完全不依赖CFG,DiffusionNFT也能在美感、对齐度等方面显著优于原始模型。在多奖励联合优化测试中,DiffusionNFT在所有指标上均超越原始模型,与只针对单一奖励进行优化的FlowGRPO持平,并超过更大规模的SD3.5-L与FLUX.1-Dev模型。
DiffusionNFT的提出不仅为扩散模型的强化学习提供了高效、简洁且理论完备的新框架,也对更广泛的生成模型对齐研究具有启发意义。该方法展示了负例感知与前向一致性的普适价值,打破了似然估计与反向轨迹的限制,建立起监督学习与强化学习之间的桥梁。在未来,DiffusionNFT有望推广至多模态生成、视频生成以及大模型对齐等更复杂场景,成为统一的生成优化范式。
原文和模型
【原文链接】 阅读原文 [ 1387字 | 6分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★☆☆☆


相关文章


