文章摘要
【关 键 词】 AI生成、视觉模型、自监督学习、VAE替代、语义空间
AI图像生成技术正在经历一场范式转变,传统的VAE(变分自编码器)技术逐渐被更先进的方案取代。长期以来,扩散模型依赖VAE压缩图像以降低算力成本,但VAE构建的潜空间存在语义混乱的缺陷,导致不同概念的特征纠缠,影响训练和推理效率。清华大学与快手可灵团队提出的SVG(自监督视觉生成)方案,以及谢赛宁团队的RAE(表征自编码器),均指向了无VAE的未来。
VAE的核心问题在于其潜空间缺乏清晰的语义结构。例如,在VAE空间中,猫和狗的特征可能混杂,模型需耗费大量训练步数才能理清分布。相比之下,自监督模型(如DINOv3)构建的特征空间语义分明,更适合扩散模型训练。SVG的创新在于直接利用DINOv3的预训练特征作为语义骨架,辅以残差编码器补充高频细节,并通过分布对齐机制确保特征融合的稳定性。
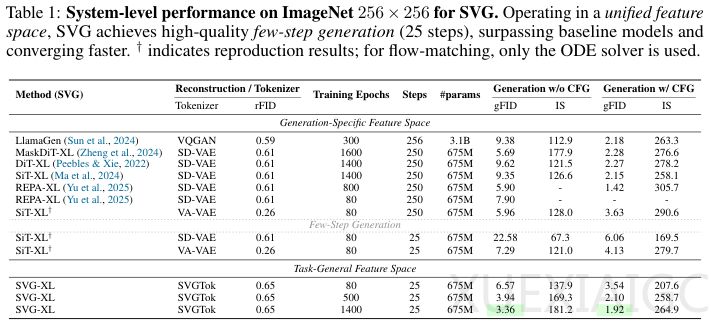
SVG在生成质量、效率和通用性上均超越传统VAE方案。实验显示,SVG-XL模型在ImageNet数据集上的FID(Frechet Inception Distance)指标显著优于VAE-based模型,训练效率提升17.5倍。在少步采样条件下,SVG仍能生成高质量图像,而VAE模型则表现不佳。此外,SVG的潜空间可直接用于分类、分割等视觉任务,无需额外微调,验证了生成与理解能力共享统一表征空间的可行性。
SVG的设计结合了语义骨架与细节重构,为通用视觉模型提供了新路径。其潜空间不仅支持平滑的图像插值和零样本编辑,还证明了高维特征空间的训练稳定性。尽管SVG在更高分辨率任务中的潜力有待探索,但它标志着AI视觉技术向“能看懂也能创造”的统一目标迈出了关键一步。
原文和模型
【原文链接】 阅读原文 [ 2231字 | 9分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★☆


相关文章


