登顶开源SOTA!上交大&小红书LoopTool实现工具调用任务的「数据进化」
文章摘要
【关 键 词】 大语言模型、工具调用、数据优化、闭环训练、开源模型
大语言模型与外部工具的结合已成为推动AI从“会说”走向“会做”的关键机制。这种结合在API调用、多轮任务规划、知识检索和代码执行等场景中尤为重要。然而,现有的数据生成与训练流程通常是静态的,数据在训练前一次性生成,无法感知模型能力的动态变化。这种静态方法可能导致模型对简单任务重复学习,浪费算力,同时难点样本长期缺乏优化。此外,许多现有流程依赖昂贵的闭源API生成与评估数据,而开源替代方案往往引入大量噪声标签,降低训练效果。
上海交通大学与小红书团队提出的LoopTool框架解决了这些问题。LoopTool是一个自动的、模型感知的、迭代式的数据进化框架,首次实现了工具调用任务的数据–模型闭环优化。该框架仅依赖开源模型Qwen3-32B作为数据生成器与判别器,无需闭源API支持。通过这一框架,一个8B规模的LoopTool模型在工具调用表现上显著超越其32B数据生成器,并在BFCL-v3与ACEBench公开榜单上取得同规模模型的最佳成绩。训练后的LoopTool-32B模型也在这两个榜单上登顶,验证了闭环迭代优化在不同模型规模上的通用性与有效性。
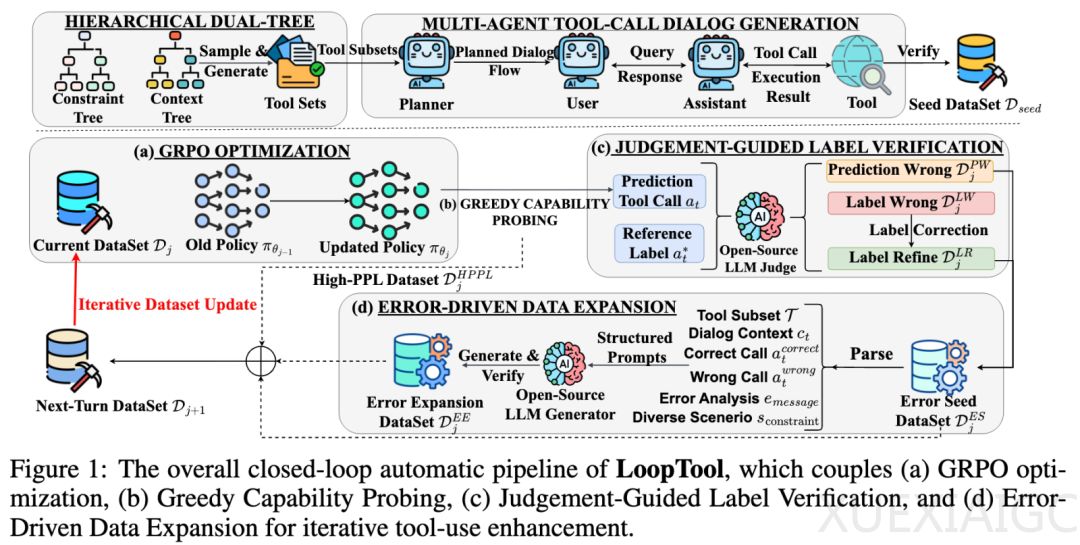
工具增强型大语言模型已在多领域证明其价值,但要让模型稳健地使用工具,需要持续提供与其当前水平匹配的高质量训练数据。目前主流方法采用静态流程,缺乏对模型学习状态与短板的实时反馈。此外,使用闭源生成/评估模型成本高,而开源模型则容易引入标签错误。LoopTool的核心思想是让数据生成、标签修正与模型训练形成自动化闭环,由模型性能反馈驱动下一轮数据优化。这一过程包括种子数据构建与迭代优化闭环两大阶段,后者细分为四个核心模块:GRPO强化学习训练、贪婪能力探测、判别引导标签校验和错误驱动数据扩展。
在实验中,研究团队选用开源Qwen3-8B和Qwen3-32B模型作为基础模型。LoopTool-8B在BFCL-v3榜单上总体准确率达到74.93%,较原始Qwen3-8B提升8.59个百分点。LoopTool-32B则以79.32%的总体准确率位列第一。在ACEBench评测中,LoopTool-8B以73.4%总体分数夺得同规模第一,LoopTool-32B达到开源模型榜单中的最佳成绩。消融实验显示,高困惑度样本筛选、判决引导标签校正和错误驱动数据扩展模块对性能提升均有显著贡献。
LoopTool的闭环优化不仅增强了工具调用能力,还提升了模型的泛化推理与复杂任务处理能力。在通用任务测试中,LoopTool-8B在全部任务上匹配或超越原模型,尤其在指令跟随与代码生成上提升显著。LoopTool-32B则在数学任务上超越原始模型。下游任务评测进一步验证了LoopTool在实际问题解决中的有效性。
LoopTool呈现了一个完全自动化、模型感知的闭环管道,将数据合成、标签校正与模型训练紧密结合。整个过程完全依赖开源模型,降低了成本并确保了数据质量。通过多轮迭代,LoopTool不断针对模型薄弱点合成更具挑战性的样本,同时校正噪声标签,让训练数据随模型能力提升而动态进化。这一框架不仅证明了模型闭环进化的有效性,也展示了开源框架在无依赖闭源API条件下实现卓越表现的可能性。
原文和模型
【原文链接】 阅读原文 [ 3944字 | 16分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


