文章摘要
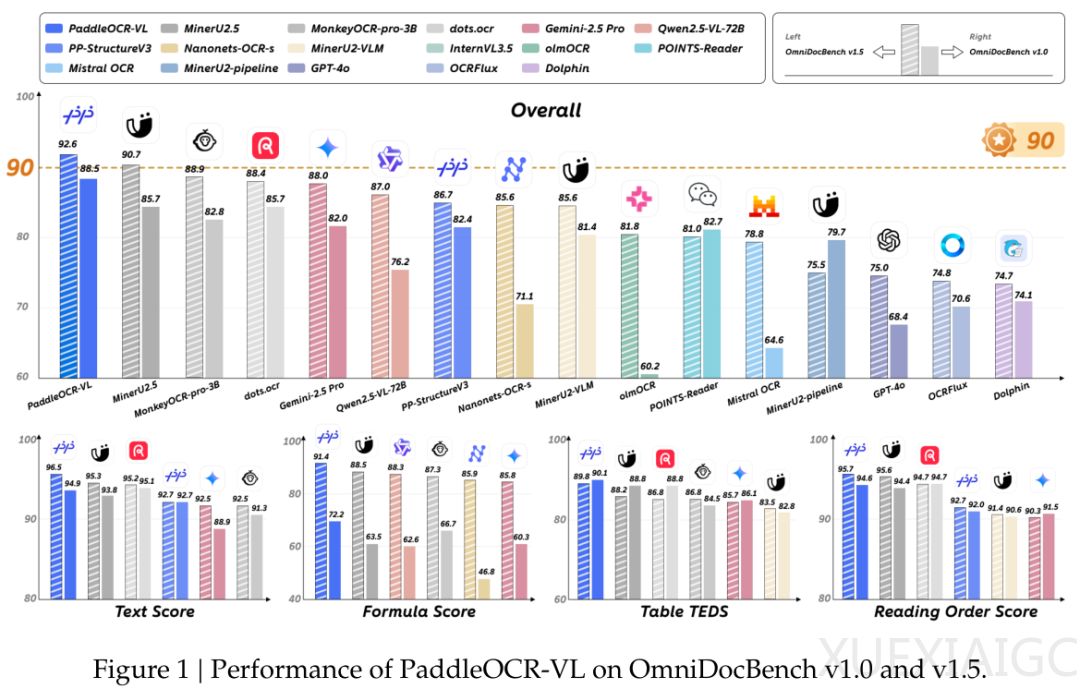
百度推出的PaddleOCR-VL模型在文档解析领域取得了突破性进展。这个仅0.9B参数的模型在权威评测OmniDocBench V1.5上以92.6分的综合成绩位列全球第一,同时在文本识别、公式识别、表格理解和阅读顺序四个核心维度上均达到业界最佳水平。该模型能处理109种语言,覆盖全球主要语言体系,展现了出色的多语言处理能力。
模型的设计采用了创新的两阶段架构。第一阶段使用PP-DocLayoutV2布局分析模型,通过RT-DETR检测模型和轻量级指针网络精确识别文档元素的位置和阅读顺序。这种设计借鉴了Relation-DETR的几何偏置机制,能准确理解元素间的空间关系,确保拓扑一致性。第二阶段则由0.9B参数的PaddleOCR-VL-0.9B模型负责各区域的精细识别,包括文本、表格、公式等内容。
在技术实现上,模型采用了多项创新:NaViT风格的动态分辨率编码器保留了文档细节,0.3B参数的ERNIE-4.5-0.3B语言模型保证了推理效率,3D-RoPE技术增强了位置感知能力。这种组合使模型在保持高性能的同时,实现了更低的内存占用和更快的处理速度。
在OmniDocBench V1.5评测中,PaddleOCR-VL展现出全面优势:文本编辑距离0.035、公式CDM得分91.43、表格TEDS 89.76、阅读顺序编辑距离0.043,各项指标均为最佳。模型每秒可处理1881个Token,比同类产品快14.2%-253.01%,在A100 GPU上表现出色。
成功的背后是庞大的训练数据支撑。研发团队构建了超过3000万样本的数据集,结合公开数据、合成数据和网络抓取数据,并通过自动化标注流程确保质量。采用专家模型生成伪标签,再用大模型优化增强,最后进行幻觉过滤,形成高质量训练数据。此外,困难案例挖掘机制针对模型弱点生成专项训练样本,持续提升性能。
PaddleOCR-VL的成功标志着文档解析技术从传统OCR向多模态理解的重大演进。其两阶段架构在性能与效率间取得平衡,为资源受限环境提供了优质解决方案,展现了小模型在大规模应用中的潜力。
原文和模型
【原文链接】 阅读原文 [ 3366字 | 14分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


