文章摘要
【关 键 词】 通义千问、能效优化、多模态、长上下文、开源模型
模型性能极限突破放缓,但模型进化依然在向着极致的能效加速,新一代语言系统摆脱单纯堆砌物理算力的传统路径,转而依靠混合计算网络、高质量清洗数据及强化学习算法协同运作,大幅降低硬件部署门槛,在多模态理解与超长文本处理等维度取得量化性能提升。
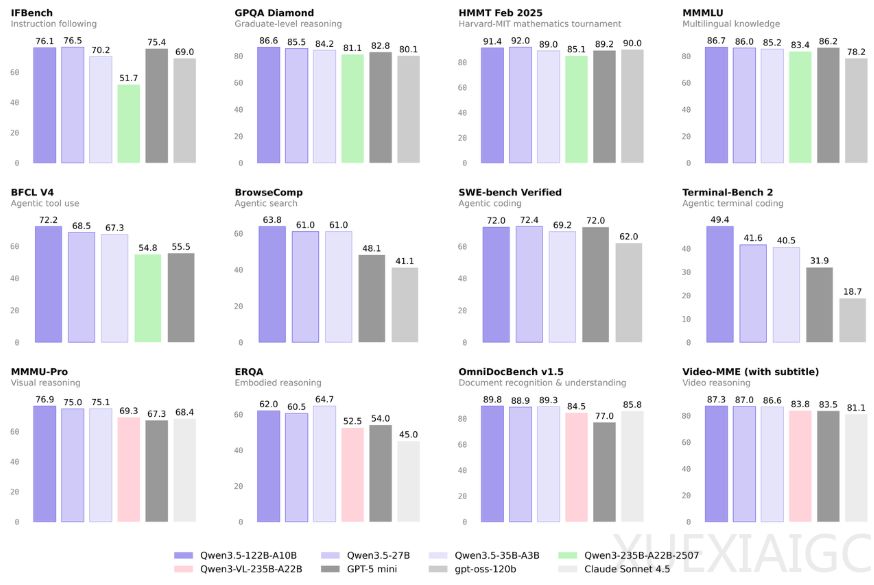
阿里通义千问研发团队推出涵盖多层次参数规模的开源模型矩阵,以架构与数据驱动模型能力进化。单纯堆砌物理参数无法持续提升系统智能。精巧的混合计算架构结合高质量数据与RL(强化学习)引擎铺垫了更加高效的技术进化之路。该矩阵包含多个精准定位的细分版本:122B参数模型搭建起开源社区与前沿闭源计算中心的性能桥梁,在多步逻辑推理、跨应用操作等复杂智能体任务中表现扎实;35B参数版本在多项核心指标上超过7个月前发布的235B大参数版本,直接验证技术重心的转移;27B参数的密集型版本为算力有限场景提供高能效备选方案,且在4-bit权重量化与KV Cache量化处理下仍维持原有计算性能,切实降低初创团队的技术接入门槛。
系统在底层基础训练阶段做出了关键性结构调整,让模型在多模态Token的早期融合阶段就开始同步吸收不同维度的知识,视觉图像与纯文本在模型训练初期实现交织计算,使系统在逻辑编码推理及深度视觉理解上全面追平同代产品、反超以往单独优化的视觉前置模型,可准确解析复杂医疗影像与抽象数学图形。门控增量网络与稀疏MoE机制组成高效底层框架,接收复杂提问后可精准唤醒对应领域专家模块,在保持高吞吐推理速度的同时,缩减响应延迟与服务器算力成本。
超长上下文窗口是本次模型升级的实用亮点:27B参数版本可流畅处理超80万个Token的文档,35B参数版本在单张32GB显存的消费级GPU上即可稳定吞吐100万规模上下文,122B参数版本仅需80GB显存服务器即可实现同等分析深度。基于35B的Qwen3.5-Flash API在阿里云百炼云平台全线开放,默认支持100万上下文长度且预装原生工具链,省去开发者调试步骤。此外,模型经强化学习训练具备优秀软件工程能力,支持201种小众语言与方言,多模态联合训练效率贴近纯文本训练峰值,基础模型源代码同步对外开放给全球科研人员。
原文和模型
【原文链接】 阅读原文 [ 1664字 | 7分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 doubao-seed-1-8-251228
【摘要评分】 ★★★☆☆


相关文章


