糟糕,大佬45年前论文,被判AI生成
文章摘要
【关 键 词】 AIGC检测困境、AI误判频发、训练数据回环、学术界受冲击、经典文本被误判
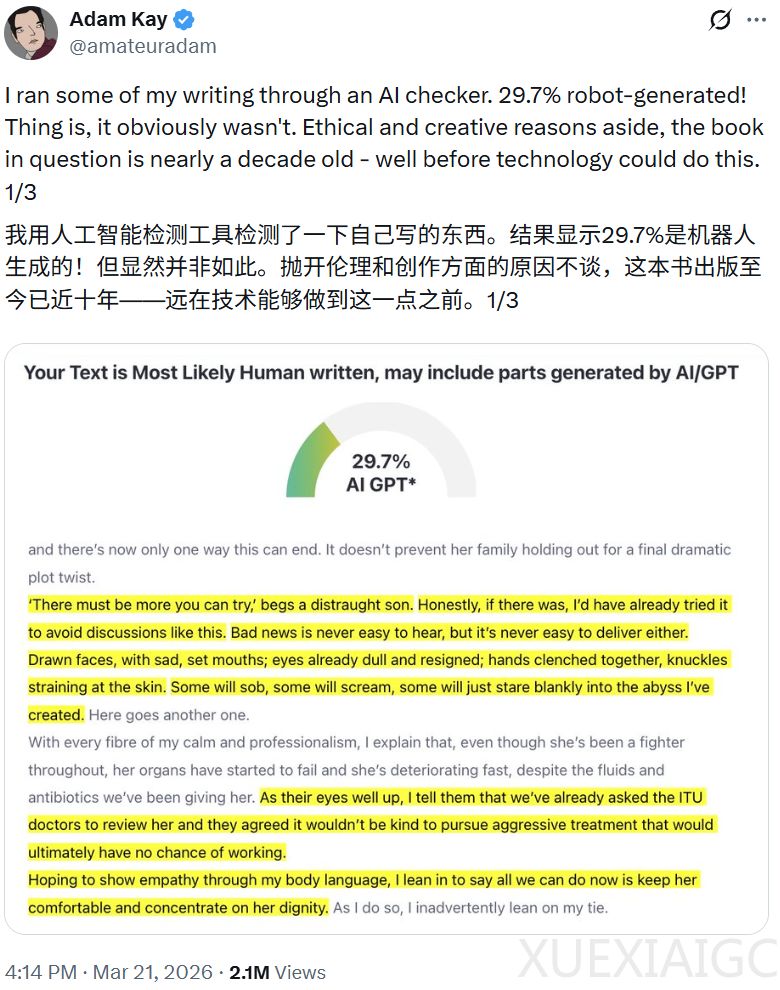
当前AI内容检测技术面临严峻挑战,其准确性远低于预期。多个真实案例显示,系统频繁将人类早期创作、经典文献乃至新闻报道错误判定为AI生成。知名作家Adam Kay提交十年前已出版的作品,检测器竟称29.7%为AI生成;爱丁堡大学Devil Sridhar教授过往文章被标为90% AI生成;阿伯丁大学Paul Spicker教授45年前论文亦遭77%误判。更极端的是,网友用2008年自身论文测试,获100%纯AI结论;Zavinski的2000字本地历史报道因平实文风仍被定为91% AI可能,并附“可读性差”负面评价。连莎士比亚名剧《罗密欧与朱丽叶》被标注41% AI成分,《独立宣言》则被判定99.99%由AI生成。
问题根源在于模型训练机制的逻辑悖论:当前检测工具多基于大量人类文本进行训练,因此其识别特征本质是对人类表达模式的再学习;当它识别出某段文字具有AI风格时,实则是模型在复现其曾学习过的海量人类写作痕迹。这种“用人类知识反推人类作品”的闭环逻辑使检测系统陷入自指困境——作者使用语言越规范、词汇越丰富,越易触发检测规则,导致“写作越优秀反而越易被误判”现象。
该系统还衍生出连锁反应:如破折号识别法已被广泛采纳,迫使创作者改变书写习惯;未来若出版商普遍采用AI检测作为校验流程,那么大量曾用于训练模型的人类著作,恐将面临系统性误判风险。有专家指出,“AI检测器本质上是胡扯”,因其构建逻辑依赖于“先用人类智能训练AI,再用该AI判定内容是否出自AI”的自我矛盾链条;此类判断既缺乏可靠性依据,亦违背公平原则,更在逻辑上无法自洽。由此引发的根本性疑问是:当AI本身即源于人类创作时,“是否像AI”这一标准早已失去清晰界限,检测机制本身或已丧失区分真伪的客观基础。
原文和模型
【原文链接】 阅读原文 [ 1160字 | 5分钟 ]
【原文作者】 机器之心
【摘要模型】 qwen3-vl-flash-2026-01-22
【摘要评分】 ★☆☆☆☆


相关文章


