统一框架下的具身多模态推理:自变量机器人让AI放下海德格尔的锤子
文章摘要
当前最先进的机器人在工具使用上仍面临显著挑战,无法像人类一样直觉地操作工具。它们每次使用工具时都需要重新识别和规划,这种割裂式的处理方式限制了其能力。具身智能的突破需要一场架构革命,而非对现有视觉-语言基础模型的修补。自变量机器人提出,必须放弃多模态模块融合的拼凑式范式,转向端到端的统一架构,彻底消解视觉、语言和行动之间的边界,将它们还原为单一信息流。
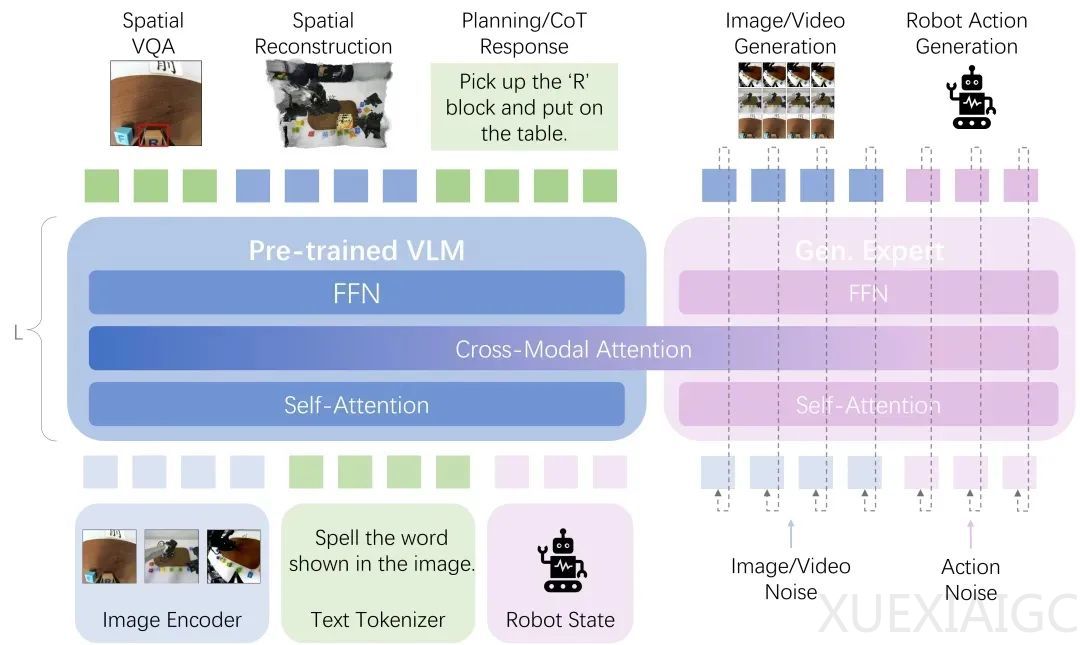
现有主流方法将不同模态视为独立模块,通过融合层连接,但存在表征瓶颈和无法涌现的问题。信息在不同模态的专属编码器之间传递时,会产生不可避免的压缩损失,阻碍模型对物理世界进行深层次的跨模态理解。结构上的割裂使得模型难以学习到物理世界中跨越模态的、直觉式的因果规律。真正的物理智能需要整体性的、具身的理解,而非模块化的知识拼接。
自变量机器人提出的统一模态架构源于一个核心洞察:真正的具身智能应在统一的计算框架内同时处理感知、推理和行动。架构的核心是统一表示学习,将所有模态信息转换为共享的高维 token 序列,消除模态间的人为边界。关键突破在于采用多任务多模态生成作为监督机制,迫使模型建立起深层的跨模态对应关系。具体而言,所有输入模态通过各自的编码器转化为统一的 token 序列,送入一个 Transformer 核心,实现端到端的统一学习。
这种架构实现了具身多模态推理的涌现。当面对新任务时,系统能够像人类一样进行整体性认知处理,视觉理解、语义推理、物理预测和动作规划在统一空间内并行发生、相互影响。通过这种端到端的统一学习,系统最终能够像人类一样思考和工作,不再依赖模块化的信息传递,而是在深层表示空间中直接进行跨模态的因果推理和行动决策。
统一架构旨在解锁当前模块化系统无法实现的全方位具身多模态推理能力。第一个是符号-空间推理能力,机器人能够理解复杂几何图案,进行多层次推理,并转化为三维空间中的物理操作。第二个是物理空间推理能力,机器人能够理解积木的放置如何影响整体结构的稳定性,推断操作顺序背后的工程逻辑,并预测不同操作路径可能导致的结果。第三个突破是具备推理链的自主探索能力,系统能够整合视觉观察、空间记忆和常识知识,构建出连贯的推理链条。
最后一个展示了机器人从视频中学习能力和协作推理能力。机器人能够从视频中推断行为背后的深层意图和目标状态,超越简单的动作模仿,展现真正的自主学习和人机协同能力。
这些演示背后体现的是一个根本性的范式转换。传统的多模态系统将世界分解为独立的表征模块,但物理世界的交互是连续的、实时的、多模态耦合的。自变量机器人的统一架构正是为满足这种具身交互的要求而生。这种转变的意义在于,它让机器人能够像海德格尔描述的熟练工匠一样,将感知、理解和行动无缝融合。
机器人不再需要经历“视觉识别→语言规划→动作执行”的冗长串行处理,而是在统一的表征空间中被直接理解为实现特定意图的媒介。机器人能够同时“看到”物理属性、“理解”其在任务中的作用、“感知”操作的空间约束,并“规划”相应的动作序列。正是这种多模态信息的并行融合处理,使得具身多模态推理能力得以自然涌现,让机器人最终能够像人类一样流畅地与物理世界交互。
自变量机器人主张,具身智能的未来路径是从设计“割裂式表征”的系统,转向构建能够进行真正具身多模态推理的统一系统。这并非一次增量改进,而是让 AI 具备跨模态因果推理、空间逻辑推演和实现通用操作的具身智能所必需的架构进化。
原文和模型
【原文链接】 阅读原文 [ 2353字 | 10分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章


