文章摘要
【关 键 词】 视频生成、多模态、深度学习、计算机视觉、人工智能
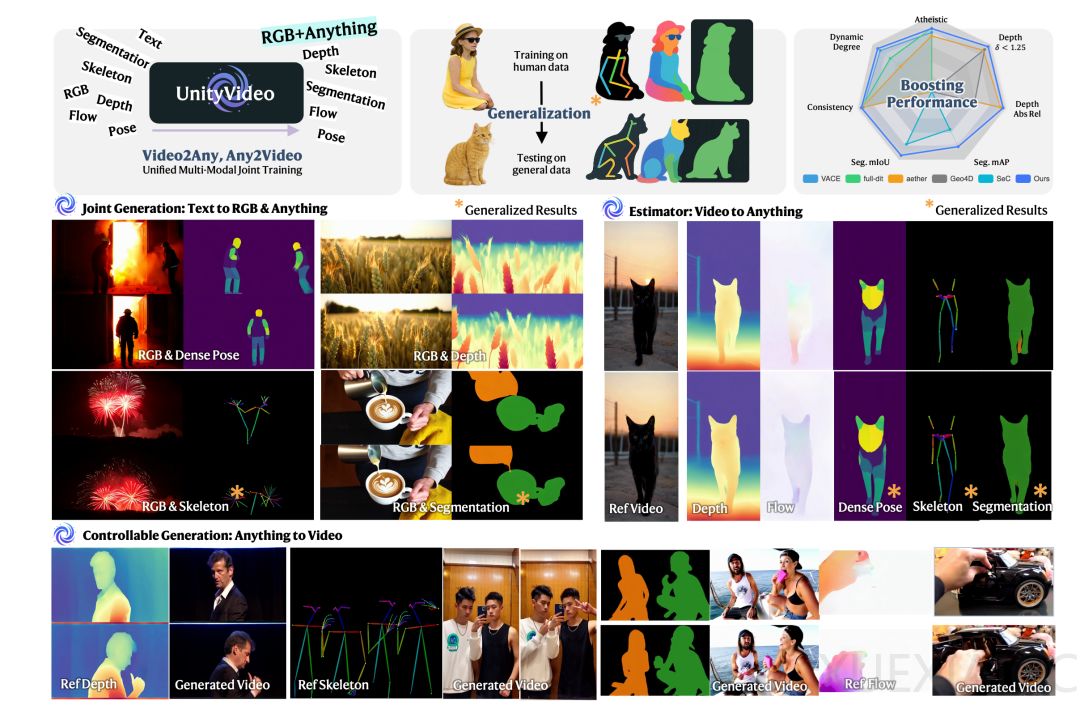
统一多模态多任务的视频生成模型UnityVideo通过整合多种视觉模态,显著提升了模型对物理世界的理解能力和生成质量。该模型由港科大、港中文、清华大学和快手可灵的研究团队联合开发,其核心创新在于将深度图、光流、骨骼、分割掩码等多种视觉模态统一训练,使模型能够更全面地理解场景的几何结构、运动模式和物体关系。这种多模态联合训练不仅加速了模型收敛,还带来了性能的显著提升,特别是在物理现象建模和零样本泛化方面展现出突出优势。
UnityVideo的技术突破主要体现在动态任务路由、模态切换器和渐进式课程学习三个方面。动态噪声调度策略使模型能够同时支持条件生成、模态估计和联合生成三种训练范式,避免了传统方法中的灾难性遗忘问题。模态自适应切换器通过为不同模态设计独立的调制参数,实现了即插即用的模态选择能力。两阶段课程学习策略则从基础的空间对应关系训练开始,逐步扩展到更复杂的多模态场景,确保了训练的稳定性和有效性。
为支持这一创新框架,研究团队构建了包含130万样本的OpenUni数据集和包含3万样本的UniBench评估基准。实验结果显示,UnityVideo在文本生成视频、可控生成和模态估计三大任务上都取得了全面领先的性能。在文本生成视频任务中,其背景一致性达到97.44%;在可控生成任务中,动态程度指标达到64.42%;在模态估计任务中,视频分割的mIoU达到68.82%,深度估计的Abs Rel仅为0.022。这些结果不仅超越了专门的单任务模型,也显著优于现有的商业系统。
模型最引人注目的特点是其强大的零样本泛化能力。仅在单人数据上训练的模型能够自然地泛化到多人场景;在人体骨架数据上训练的模型可以处理动物骨架;在特定物体上训练的深度估计和分割能力也能迁移到未见过的物体。这种泛化能力源于多模态训练带来的互补监督信号,使模型能够学习到更本质的世界规律而非简单的数据分布。用户研究进一步证实,UnityVideo生成的视频在物理质量(38.50%)和语义质量上获得了人类评估者的最高评价。
UnityVideo的成功验证了多模态统一训练在视觉理解中的关键价值。与大型语言模型通过统一多种文本子模态获得推理能力类似,视觉模型也可以通过整合多种感知信号来获得更深层的世界理解。这一发现为视频生成领域提供了新的发展方向:模型能力的提升不仅依赖于规模扩大,更在于如何有效地组织和利用多样化的学习信号。虽然当前模型在VAE重建伪影等方面仍有改进空间,但UnityVideo已经为构建真正理解物理世界的视觉大模型奠定了重要基础。
原文和模型
【原文链接】 阅读原文 [ 3702字 | 15分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


