文章摘要
美团LongCat团队发布了5600亿参数的开源全模态模型LongCat-Flash-Omni,该模型能够实现毫秒级的实时音频-视觉交互。其核心是一个端到端的全模态架构,能够接收文本、音频、图像、视频或其组合作为输入,并直接生成包含语义和情感的语音输出。模型由视觉编码器、音频处理工具、语言模型主干和流式处理机制协同工作,具备低延迟和高效率的特点。
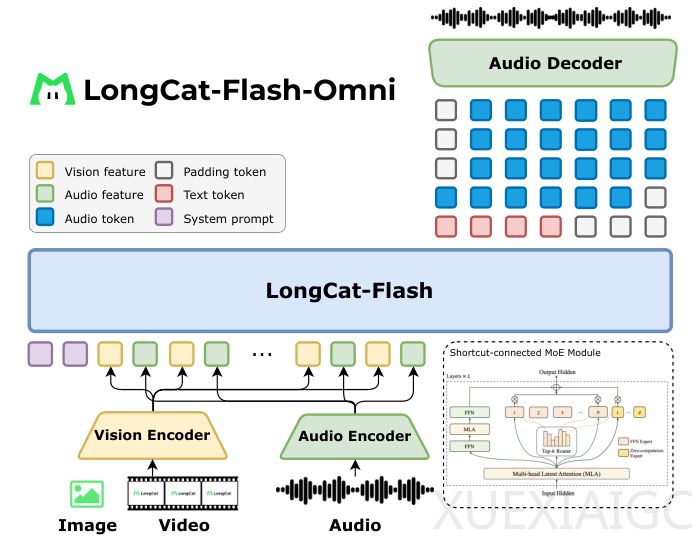
视觉编码器LongCat-ViT解决了传统模型固定分辨率的痛点,原生支持各种分辨率和宽高比的输入,最大程度保留原始信息。它采用渐进式训练方案,从低分辨率图像逐步过渡到原生分辨率,节约计算资源并提升收敛速度。音频处理方面,模型早期使用离散音频标记器,后期引入连续音频编码器以捕捉更细微的声学细节。生成语音时仍输出离散token,确保与语言模型预测范式一致。音频编码器采用流式架构,每80毫秒处理一帧,平衡延迟与性能。
模型的核心是5600亿参数的MoE语言模型,智能激活约270亿参数的相关专家,实现高效实时交互。视频处理采用动态帧采样策略,根据视频长度调整采样率,并添加文本时间戳以理解时间顺序。实时交互中,模型在用户操作时密集采样,回应时稀疏采样,降低计算开销。音频和视频特征以1秒为单位同步交错输入,确保低延迟响应。
训练过程采用课程启发的渐进式策略,分五个阶段进行。模型首先在纯文本语料上训练,逐步引入语音、图像、视频数据,最后扩展上下文长度至128000token。这种由简到繁的方法确保模型在学习新模态时不削弱已有能力。预训练后,模型经历监督微调和强化学习阶段,学习遵循人类意图并生成更符合偏好的回答。
训练中采用模态解耦并行策略,不同组件使用最适合的并行方式,通过ModalityBridge框架高效同步。团队还进行了梯度检查点、混合精度训练等优化,确保训练效率。推理框架设计为解耦服务,各模块并行工作,实现250毫秒的响应速度。
LongCat-Flash-Omni在多个权威基准测试中表现优异。图像理解方面,在VQAv2、TextVQA等基准上取得顶尖成绩;视频理解方面,在时空推理任务中表现突出;音频理解方面,超越主流模型;文本能力保持顶尖水平。综合跨模态基准OmniBench上,模型展现了强大的多模态整合与推理能力。通过统一框架,模型将离线理解与实时交互能力结合,为自然高效的人机交互奠定了基础。
原文和模型
【原文链接】 阅读原文 [ 3408字 | 14分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章


